
SBS appears to have 50 percent more advertising in some primetime hours than the SBS Act permits according to a series of findings carried out by Save Our SBS from 2009 to 2020.
Promos were not counted. Nor were classification announcements, community service announcements, sponsor billboards and sponsored promos.
Under section 45* of the Special Broadcasting Service Act 1991 advertising is limited to “not more than 5 minutes in any hour of broadcasting”. Promos do not count as an advertisement and the Act excludes them from counting in the 5 minute hourly cap*.
Out of 66 hours of primetime logging, Save Our SBS detected 22 hours that would appear to contain more than 5 minutes of advertisements per hour — without counting promos. When promos were counted, SBS had up to 15 minutes of non-program matter (ads plus promos).
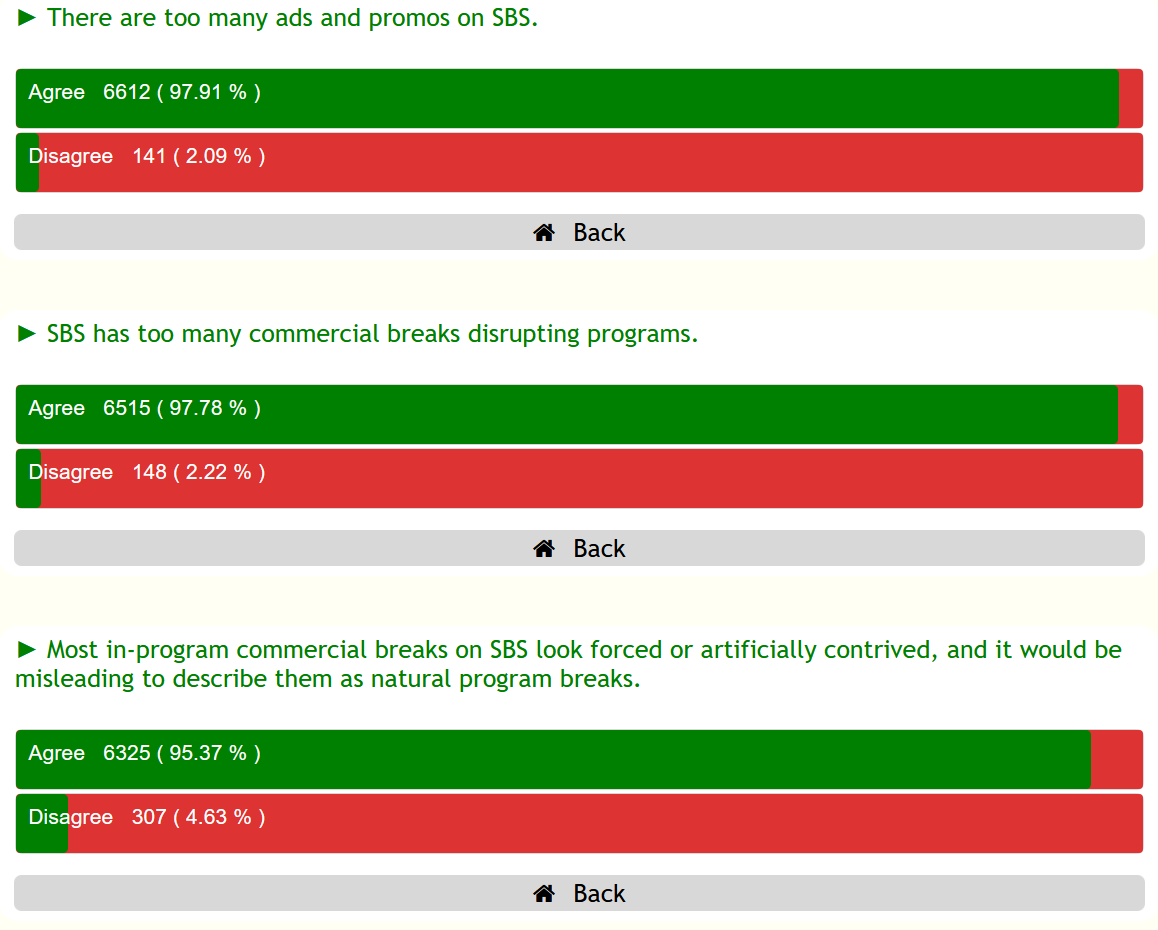
The THREE QUESTION POLL results are here.
In one-third of random primetime logging spread over 10 nights — 6 PM to midnight — the logs detail what appears to be up to a 50 percent overrun of advertising.
However, the logs show that generally SBS carried around 30 minutes of ads over a six hour period (which averages to 5 minutes per hour) plus a similar amount of promos. An excess of ads in one hour was usually offset by an underrun in another hour. SBS is not permitted to average advertising across the day. The parliament rejected that idea in 2015 and 2017, signalling SBS must not exceed the 5 minute hourly advertising cap.
Although most viewers can tell a promo from an advertisement, the average viewer may mistake some spots — that clearly are not promos nor community service announcements — as ads.
The SBS Act exempts spots from inclusion in the 5 minute hourly advertising count for SBS products, services or activities, and community information or material where SBS did not receive any consideration in cash or in kind*. If a spot appeared to genuinely fit the exemption, the spot was not counted in the 5 minute hourly advertising count. However, as SBS does not caption ‘community service announcements’ nor identify if a spot satisfies the exemption criteria, it was difficult to be sure if SBS applied an exemption or why. On-air transparency to confirm exempt spots was lacking.
At times, SBS associated itself with a large international private company under the guise of organising a community event but the private company claimed ownership of the advertised product charging consumers hundreds of dollars for it.
Spots for commercial money making ventures were logged as advertisements.
Save Our SBS first began monitoring SBS transmissions back in 2009 for internal use only to understand the detail behind complaints that ‘SBS looked too commercial’. The historical logs showing the hourly advertising excesses were publicly released in evidence before a Senate Committee in 2015.
Following historical and recent complaints to Save Our SBS claiming an excessive number of ads, too many commercial breaks, and breaks that appeared forced (instead of natural), Save Our SBS resumed random primetime logging mid year, only to discover after five nights, there was at least one hour — and often more — every night, in which SBS appeared to exceed the 5 minute hourly ad limit, except on NITV.
In today’s digital age, it is an easy task to run software that continuously checks every second of the day, that the previous hour — up to the moment of the check — did not exceed 5 minutes of ads.
The ADS column below indicates the hour in which more than 5 minutes of advertising was logged. PMO refers mainly to promos and spots that were not logged as an advertisement. The non-program matter (ads plus promos etc) appears in the TOTAL column. The durations are in minutes and seconds.
| CHANNEL | DATE | HOUR | ADS* | PMO | TOTAL |
| Food | 4/6/20 | 10PM-11PM | 7:30 | 7:15 | 14:45 |
| Food | 4/6/20 | 7PM-8PM | 6:00 | 6:55 | 12:55 |
| World Movies | 3/6/20 | 10PM-11PM | 5:30 | 1:45 | 7:15 |
| World Movies | 3/6/20 | 8PM-9PM | 5:30 | 2:45 | 8:15 |
| World Movies | 3/6/20 | 6PM-7PM | 5:15 | 4:15 | 9:30 |
| VICELAND | 2/6/20 | 8PM-9PM | 7:00 | 6:50 | 13:50 |
| VICELAND | 2/6/20 | 6PM-7PM | 5:30 | 5:45 | 11:15 |
| Primary | 1/6/20 | 6PM-7PM | 5:30 | 3:45 | 9:15 |
| TWO | 20/2/14 | 11PM-12MN | 5:30 | 3:31 | 9:01 |
| TWO | 20/2/14 | 9PM-10PM | 6:00 | 6:47 | 12:47 |
| TWO | 20/2/14 | 8PM-9PM | 5:30 | 10:34 | 16:04 |
| ONE | 13/2/14 | 10PM-11PM | 6:00 | 5:15 | 11:15 |
| ONE | 13/2/14 | 7PM-8PM | 5:30 | 3:55 | 9:25 |
| ONE | 6/6/12 | 11PM-12MN | 6:00 | 3:09 | 9:09 |
| TWO | 8/4/11 | 9PM-10PM | 5:30 | 2:37 | 8:07 |
| TWO | 8/4/11 | 7PM-8PM | 5:45 | 9:24 | 15:09 |
| ONE | 7/4/11 | 10PM-11PM | 6:15 | 2:59 | 9:14 |
| ONE | 7/4/11 | 9PM-10PM | 6:00 | 4:23 | 10:23 |
| ONE | 7/4/11 | 7PM-8PM | 6:00 | 4:36 | 10:36 |
| SBS ONE | 10/11/09 | 10PM-11PM | 5:30 | 2:12 | 7:42 |
| SBS ONE | 10/11/09 | 9PM-10PM | 6:00 | 3:23 | 9:23 |
| SBS ONE | 10/11/09 | 7PM-8PM | 6:30 | 3:05 | 9:35 |
In the logs of 2 June this year, SBS VICELAND appeared to exceed the advertising limit in two separate primetime hours. The channel was logged having 40 percent more ads than permitted from 8 PM to 9 PM with ads saturating the popular “8 Out of 10 Cats” program. It ran 47 minutes but occupied an hour slot. The 6 PM to 7 PM hour appears to have exceeded the limit by 10 percent. Each hour totalled 13 minutes and 50 seconds, and 11 minutes and 15 seconds respectively of non-program matter. That is on a par with commercial television.

Similarly, on 4 June SBS Food was logged as having 7 minutes and 30 seconds of ads (50 percent over the limit), on top of 7 minutes and 15 seconds of promos, disrupting the program with 14 minutes and 45 seconds of non-program matter from 10 PM to 11 PM. On the same SBS channel, the 7 PM to 8 PM hour was logged as carrying 6 minutes of advertising (20 percent above the limit), plus 6 minutes and 55 seconds of promos, totalling 12 minutes and 55 seconds of non-program matter. There were around 36 minutes of promos that night from 6 PM to midnight.
The logs confirm a lot of clutter in every break on SBS. The broadcaster places around 10 spots in each commercial break with a high number of promos additional to ads.
SBS uses promos as timing adjustments so each program commences at the publicised time. There was a time — in the distant past — when SBS had less promos and ran hostings and short programs scheduled to fill, enabling each program to begin on time.
On the SBS World Movies channel there were three separate hours logged as exceeding the 5 minute hourly advertising cap on 3 June, while there was one such hour on 1 June on SBS’s primary channel. Every hour 6 PM to midnight averaged about 10 minutes of non-program matter per hour.
All logging was of SBS transmissions in Melbourne, detailing down to the precise second exactly what went to air and its duration. The complete logs are at the links below:-
|
On 9 April last year, SBS’s Managing Director, James Taylor told Senate Estimate that the SBS Board imposed a set of “director KPIs” relating to him and his team measuring what he is accountable for; SBS’s “core commercial revenue”. That’s advertising. The extent to which bonuses are paid on an ability to maximise commercial revenue was not detailed but at an Estimates hearing on 3 March this year Mr Taylor said their “best practice is to minimise disruption to audiences” in the placement of ads. That statement does not fit with 5,000 viewers of a 300 page report who say there are too many disruptive commercial breaks and too many ads on SBS. The report was forwarded to SBS.

Worst of all are the gambling ads. Whilst realising revenue has to come from somewhere, please explore avenues other than promoting gambling and junk food.
There are far too many ad breaks on SBS. It ‘s more unwatchable now than ever.
We can’t stand the number of commercial breaks anymore.
Surely the board and management must know just how annoying it is.
If you can’t get rid of the ads, at least have less commercial breaks!
One break every 30 minutes we could cope with but not the current number.
And why are there so many promos? We end up switching off.
None of the breaks look natural ever. They’re obviously all forced into the program. Contrived is the word, not natural. All of them.
Keep your ads if you want sbs but just give us less interruptions.
The length of the ad breaks are really bad and make programs very disjointed.
It is so very annoying and seems to be worse than ever.
Agree 100% that there are too many gambling ads. One gambling ad is one too many.
Constant breaks with the SAME repetitive ads. Sometime the same ad twice in one break
There are too many advertisements and the amount or repeats is enough to drive anyone insane.
Please remove all gambling ads from SBS.
I COULD NOT BELIEVE THE NUMBER OF ADDS THE OTHER NIGHT, ONE AFTER ANOTHER, WHERE I kept saying to myself, that surely is end. I was not counting from the beginning, but it seemed like roughly 15 ads, some short, some not so short,one after another. My wife and I both said: This is ridiculous.
SBS is becoming unwatchable with the excessive number of ads in prime time viewing. Please reduce.
SBS should not need ads to maintain its financial stability – it should be adequately funded from public sources – governments, including the current commonwealth government, talk of the benefits of a multicultural society and like to take credit for them – they should put their money where their mouth is.
The ads on SBS are totally disruptive, I now record all programs that i want to watch and play them back skipping the ads.So i’m not seeing any ads at all!
How is this amount of promo and advertising material simply allowed when the SBS is a public body? The Coalition is always quick to clamp down on every other aspect of our public broadcasting.
Like my friends I record SBS programs so that I can delete the ads. That means advertisers are wasting their money on us.
Privatisation is a massively failed project of the deeply iniquitous neoliberalism. A return to Keynesianism (which saved the world from the Great Depression and is doing so now with COVID-19) would see our national multicultural broadcaster, SBS, return to be entirely publicly funded. Our pre- and post-second world war grandparents had the balance right!
The number of ads in a row is ridiculous. We used to watch just SBS and ABC. Now it’s pretty much just ABC because of the number of, and frequency of, ads.
The gambling ads in particular are worrying – they are unethical.
We’ve changed to watching Netflix programs because of over-advertising. Would prefer to watch SBS without ads.
The commercial ads on SBS have ruined viewing pleasure, it is a great tragedy that our federal government is so opposed to public broadcasting, especially when the quality of commercial TV is so poor.
Carolyn
Given the destruction caused by gambling, I think advertising it is unconscionable. I resent gambling being ‘normalized”, and seen as an inevitable part of ‘sport’. What do we expect our kids to learn from this?
Streaming adverts are a pain. If you try to scan through to a particular place in a program you cannot miss out the adverts.
Please give us back our original SBS and leave the heavy advertising to the commercial channels, as was originally intended.
SBS was once a place for honest docos, enlightened world news and refreshing content.
Now it’s car ads and other junk etc which barely distinguishes it from regular commercial nonsense.
Please return this channel to it’s rightful dignified place.
Cut the nonsense and properly fund it. When ads come on I often switch over or off (or go on the internet.).
There’s enough noise and insanity in the world already.
SBS is better than that. Please take this on board and thanks for reading.
In particular, I object to promotion for a different program appearing all the time on the bottom right of the screen while I am watching a chosen program.
I agree that SBS has far too many advertisements because it is inadequately funded by the current NLP Government. SHAME on them !!
We should have seen it coming! A few innocent ads on SBS…the thin edge of the wedge. It’s now close to unwatchable television.
The ads in SBS On Demand are also infuriating! A lot of the ads are just self-promotions for other SBS programs – so why interrupt the program at all?. I am really put off watching SBS free to air and SBS On Demand.
I agree with Bob Y and hence have diminished my watching of SBS to a large extent, even the SBS news which we used to love. So sad.
Amanda
Ad and promo breaks are too long on SBS, often disrupting tension or story line.
Some ad topics such as gambling are abhorrent and should not be broadcast at any time.
Limit the number of breaks if we must have ads. But why do we have to have ads at all?
We always watch ABC now although their promos are annoying too. Which is a shame as SBS have some really good programs.
And when we do watch SBS the mute button is never very far away.
The 3 or 4 ad breaks in programs that I view really ruin the shows. I don’t watch them anyway, I start switching channels & come back when I think the ads are over.
I am also troubled with the number of ads for betting agencies. But want to praise the excellent Indigenous channel for its content, which would be even better if there were not so many ad breaks during programs.
Far too many ads and promos and lengthy ones at that. If SBS wants an audience they are going to have to rethink this situation. It’s just become another awful commercial station.
I agree there to many ads, I especially dis like the ads promoting gambling
Yes – please explore avenues other than those promoting gambling and junk food.
Thank Heaven for the MUTE button. The self-advertising of SBS’s own programs is just as annoying as commercial ones..
I have always loved SBS especially when it was completely publicly funded.
The content is still good but the increasing number of ads, and repeated ads have made it
so annoying.
Given its unlikely to be publicly funded again, sadly,
ads at the beginning and end of programs would be acceptable.
More funding for the Federal Government is required
The ads (no matter the art of recording then fast forewarding through the ads) simply turns me off the non ad content. It all seems to go into the mix of troubling stuff and seriously undermines the pleasure of good reporting and the excellent selection of international cinema for which SBS is recognised.
Commercial advertising on SBS undermines the purpose of SBS.
No ads would increase the pleasure and desire in viewing SBS content.
I agree wholeheartedly to get rid of the ads and promos which are ruining enjoyment of SBS. Go down to 5 mins per hour maximum.
Why does SBS have to have ads at all and if they do why DURING programs rather than at the end of or beginning of programs?
If there were far fewer ad breaks, I would watch SBS so much more often, as it is still my favourite channel!
As the number of additional and intrusive ads on SBS has increased, my program viewing has declined. I now watch few programs on SBS because of the number and frequency of the ads. I used to watch a lot of SBS programs. As watching an SBS program becomes increasingly like watching one on a commercial channel with the frequency and type of ads now being broadcast, unless this situation is reversed, I guess that I shall soon give up watching SBS completely as I have all commercial channels.
SBS should return to playing a significant part in providing information and entertainment to a multicutural Australia. It needs to do better and reign in its current advertisement actions.
Having any ads is bad enough but I am fed up program promos. The moe I see ther less I feeel inclined to watch the actual program being promoted!!
I’m grateful somebody is documenting all these sometimes harmful and always distracting ads,then trying to address the problem. THANK YOU SBS Friends
There should be no adds during a program and adds for betting and gambling should be outlawed!
I circumvent the ads by recording stuff and FF through the ads when I’m watching.
With repeats of Father Brown on ABC the only chanells worth watchong are at SBS but I’m not going to waste my life watching puerile DSP ads.
The number of ads and promotions are driving me crazy. I record everything I want to watch on SBS so I can fast forward as it has become unwatchable without doing that.
Absolutely agree about the awful gambling ads which should be banned!
A public broadcaster should not be compromised by over advertising . If it has to then let’s all agree to better funding levels. The ABC needs this certainly
The repetitive promos on SBS also drive me insane as we all have that little button on our remote that gives us a program guide that is constantly used during their commercials.
This is a slippery slope – the wedge is getting larger and larger. I tape the programs and watch later so I can zap the ad breaks.
I understand the need for adds to try &get some funds. I love SBS & I want it to have funds to keep up the excellent programmes they currently show plus the great selection of streaming movies we have with them.
SBS = Selling BS!
As a regular SBS watcher I find so may ads very distracting especially partway through a program.
The length and frequency of ad breaks has gradually increased to disturbing levels. Yet another example of LNP funding cuts and interference I suspect.
No ads, l no promos and particularly, no gambling ads.
I don’t think there’s such a thing as “sensitive placement of ads” – but that should be strived for! Fewer ads and promos, placed at beginning and end of programmes, with no more than one placed during said programme, without interfering with story line.
Abandon gambling advertising please
There are far too many breaks during programs which is a shame because I think SBS has some great content. I tend to record my favorite programs and watch them later so I can fast forward all the breaks.
The only SBS channel I watch now is NITV. At least they have NITV promo breaks rather than ad breaks.
I don’t like the ads in On Demand TV series either – there are too many per episode, most of them are targeted at people with lots of money, and they’re also repeated ad nauseam!
SBS used to be completely government funded. Since it has had to use advertisements to stay on air, the content is far less multicultural than it used to be. Much as I appreciate French and Scandinavian programs, there are probably not so many French or Scandinavian Australians! As for advertisements, I always pause the program I wish to watch so I can fast forward through the ads. If everyone did this it would completely defeat the purpose of advertisements.
SBS fills every afternoon with dodgy insurance ads concentrating on selling funeral plans, life and income replacement insurance. I expect SBS to have a higher standard than advertising these rip-off schemes.
SBS was introduced as a channel for the people but in latter years as been progressibely stripped of its charter by introducing more and more ads and promos. This is not only disruptive but downright insulting to the people who have supported the SBS. I for one am turning away from watching this channel purely due to the ads.
Counter-productive, SBS. Where once one could tolerate a few ads now one simply records for later, in order to ff through the ads and all the other disrupting, annoying, repetetitive junk. Hey presto! No rubbish food, no shouty gambling ads, no promos over and over
ads are insulting. for true entertainment don’t have ads
Nothing new: as I said before, since we find the breaks intolerable, we rarely watch SBS ‘live’ any longer . We record the programs we want to watch and fast forward through the ads or watch SBS on demand.
The aim must be to return SBS to the ad free channel it was set up to be. We can certainly afford to have two independent, taxpayer funded TV channels showing quality material. Who knows, people might actually return to FTA TV if they were not bombarded with witless ads.
In the meantime ads on SBS should be confined to between shows. Trashing art to sell things has gone far enough. Stop the ads.
Here’s hoping for pleasant viewing, ad free!
Being a migrant, I used to love watching SBS, but the often stupid and unethical adds spoil it for me. My tax money should fund this public broadcaster instead!
Too many ads. The same ad repeated over and over. Breaks at illogical times the program. Huge volume discrepancy.
Given the amount of “breaks” (read ‘advertising’) the standard of SBS is rapidly falling to below the worst of the commercial stations. SBS should remain the Special Broadcasting Service it was set up to be.
Too many adverts. The worst are the gambling adverts
SBS was never intended to be a commercial station, and should never have been forced into screening advertisements.
The ads breaks are very constant and disruptive. Often the same ad is repeated in the same segment. The gambling ads in particular do not belong on a public broadcasting screen. Why has it come to this?
Adverts are one thing…and bad enough, but SBS seems to bung them in willy-nilly. The channel is debasing what it is supposed to be doing. The SBS “product” is very good – but spoilt by the adverts.
SBS on demand is if anything worse than SBS live
OH no you just deleted my very detailed comment because I forgot to put in my name and address! Cant do it again. Please somebody somehow provide SBS and the ABC with adequate funding so we can continue to get high quality programmes and support for Australian film makers. Without having to rely on ads. What’s more regularly repeated ads during the same programme.
I’ve been grumbling on social media since the “upgrade” of SBS. There are too many disruptive breaks and they’re so repetitive with the same advertising and promos, that I feel that someone is trying to brainwash me. I hate McDonalds no matter how cute the dog is and I’ll never buy their junk food. Dare I say that I’d prefer an increase in tax, if needs be, to get this annoyance removed from SBS? I have a friend who records programs just so they can fast forward through the interruptions. Great idea.
I am annoyed by the frequency, repetition and inappropriate timing of ads on our SBS broadcasting. While I find the programmes very interesting and often inspiring, I’m deterred by the ads; even on SBS catch-up where yet another ad rudely interrupts the show and I switch off. Please make our SBS broadcaster wonderful again by reducing ads and being more thoughtful about placement.
It seems to me that SBS has left the guidelines initiated at its inception. Remember, ‘bringing the world back home’.
The content (and the various presenters) seems to be skewed toward presenting left wing , so called ‘woke’ ( I suppose meaning ‘politically correct’) philosophies.
Because of this seeming imbalances I don’t bother with SBS, or for that matter the ABC, these days.
The internet provides most of my news, current affairs and entertainment now.
It’s simple, there are just too many ads!
I agree with the earlier comment that it is preferable to record programs and fast forward over the ads. And, totally agree about getting rid of gambling ads
Jus have our government properly fund the SBS and ABC properly. Just do it, please.
I very seldom watch SBS these days due to the ads which are very intrusive. This is a shame because SBS often appears to have programs which are far more interesting than the junk on 7,9 10 and their spinoffs.I watch Netflix instead. If SBS controlled ads and reduced the interruptions I would quite possibly go back again.
Many programs on SBS I just stop watching because of 1) the irritation of the adverts themselves, and 2) the breaking of the flow of the programs.
I can remember when SBS had NO ads.
Infinitely better.
The frequency and placement of advertising is disrespectful to the viewer and all those who laboured to produce the programme being interrupted. It’s an insult.
Even worse is the repetition of the same ad or promo EVERY break. This is like waterboarding! Very offensive.
Two things
I would be willing to pay a modest Netflix-like fee not to have programs disrupted online
I can understand needing income if the gov starves you of funds. But Why Oh Why disrupt the viewing experience in the middle of a program to tell me about other SBS shows. There’s no financial benefit to SBS and it just makes viewers like me angry
It needs repeating : Too many adds
Very disappointing to have so many ad breaks on SBS. Some nights they seem to occur every 15-20 minutes. It used to be fantastic to be able to watch a movie or show with ads only appearing at the end of the programs before the next started.
There is a simple way for SBS to stop annoying their viewers and that is to only broadcast commercials BETWEEN programs and reduce their number to conform to the regulations.
Not only are there far to many ad breaks, the promos for upcoming shows which go on for weeks, are relentless.
But my biggest gripe is the willy nilly fashion in which they just chuck in add breaks; with no thought
whatsoever to the jolt you sometime experience.
Even a fade to black or a fade up from black would prepare the viewer.
Who knows, SBS may become like Youtube – you pay/subscribe to avoid the advertisements … is there a cunning plan afoot?
It needs repeating, too many adds
There are so many ads on live SBS and during programs on SBS on Demand that we have almost given up on watching. Very good programs are ruined by frequent and inappropriately timed ads.
The never-ending ads and promos are spoiling SBS viewing. I,like others
record and watch later so as to fast forward through the annoying stuff.
I am fully in agreement with the sentiments expressed in the comments made. Remedial action must be taken.
I can allow (just) ads on SBS BETWEEN programs but cannot accept or forgive the intrusion of ads WITHIN programs, especially during movies, but in ANY programming. It is an insult to both the audience and the program producers and hugely destructive of the immersive experience of watching quality programming, which is surely what SBS aims to deliver. If SBS MUST have ads to survive (because the government won’t fund it sufficiently) it should model itself on the successful and long-held practice in Germany (among other European nations) of running ads between programs only. The kind of audience SBS serves would return in droves.
Only last night my family and I commented on the incredible number of ads on SBS – on and on…. So tiresome and breaks the continuity of the main program. Thinking of going to some other form of entertainment.
Save Our SBS from Ads. Start by eliminating them from the News!
My family & I have been loyal SBS followers since its inception. It was a great, bold idea; an alternative, quality broadcaster reflecting the multi-cultural nature and interests of Australia’s population.
I appreciate SBS has to take advertising to suppliment its funding in order to do what it does, so we tolerated the European-style block adverts & promotions before & at the end of its programs.
But as SBS management obviously doesn’t understand or care about the destinctive nature of SBS’s brief, sadly it’s become like any other commercial network, driven by profit and whose sole purpose is to deliver the largest, mass audience to advertising.
So sadly for us SBS has become not only irritating, but unwatchable.
I can remember when SBS had NO ads.
Infinitely better.
Thankfully, the program content is still much better than commercial TV, so we can only hope that government funding is improved.
Have just come across this post and agree with all the above.
Certainly puts me off. Remember when ads were at end of programs and from big corporates who just put forward corporate type comments like BHP advising what they did for Aus. Which were positive and interesting and I think more effectivel for the company. The overuse of promos on SBS and ABC is annoying and of doubtful value
there are far too many ads and too many ad breaks…governments must start funding public broadcasting adequately or we shall end up with all television looking and sounding like the commercial stations – I record everything now on SBS and fast forward through the ads because even SBS on Demand is interrupted by advertising
I dislike advertisements as much as anyone else. I wonder though if most TV programs are made with only enough content to fill say ninety per cent of the allotted time, and that time has to be filled – either by promos for upcoming programs or advertisements. The length of actual content in programs made overseas would depend on whether those countries had to allow time for ads/promos as well. In our ABC programs any promos are placed between rather than during programs but with SBS they are placed during the program as well, which is the most annoying part.
SBS has great content but it’s soiled by too many ads – especially promos. I now try to record live TV and watch later so I can skip ads. However this can be inconvenient at times.
I shut the commercial television stations out of my life years ago.
I’m well on the way to doing the same with SBS.
The ABC is my last resort, and even their incessant self promotions BETWEEN programs is driving me away from television altogether.
I agree that there are too many ads on SBS and I particularly do not like anything to do with gambline/horseracing etc. I do as others do and use my dvd recorder to record programmes I want to watch in order to not sit through the ads. I would like to see these ads reduced and in the case of gambling, removed completely. People with gambling issues need our support, not advertising for something that may have already ruined their lives as well as their families with this very sad addiction. Please remove them. Thank you.
These ad breaks are extremely annoying and the reason I NEVER watch anything on SBS On Demand is because of the poxy ad breaks there… I have a download app that downloads the content WITHOUT the ads.
For some questions, I’d have like a ‘partly agree’ option. SBS does have too many ads, but I have some sympathy with this, given their inadequate funding.
SBS was/is special because of the diverse presenters and programming-the last few years have made for frustrating viewing both live and on demand because of the constant adds, they are annoying and I suggest SBS viewers are not particularly swayed by the products constantly shown.
SBS often freezes during an Ad break and I have to exit and resume and put up with the ads all over again. It may freeze during during ad 3 of 3. I then have to exit and return putting up with the opening ad, then click resume and put up with another 3 ads. In total up to 7 ads before I can continue watching. SBS self promotion is also aggravating and insulting. I do not need to be told over and over again about any program….once during a film or episode is enough for an intelligent human being to retain.
Yes it is fact, even my dog agrees, it is so obvious.
But it all comes down to one simple fact, do we want to watch a movie and be totally relaxed about it-and thus being an enjoyable experience to take us away from the stresses of daily life, OR
do we want numerous disruptions to our focus on a single thing, again creating stress by redirecting the mind in multiple directions.
This can actually drive a person insane, unless that is the intention.
So does SBS want to drive us insane as the other stations already do………OR NOT?
Remove ads which can be harmful:
– gambling
– junk food
– some drugs – in the USA drug ads MUST mention potential side effects
I know that the ads are an issue but also is the left wing reporting which seems to be a bit prevalent. Maybe if the reporting was honest and truthful more people would support the SBS and not go to the ABC though no ads but Marxist in attitude.
To make life easier for all remove ALL advertisements and rely on government as was first intended. Surely the funding of an independent SBS is more important than, for instance, wasting millions of dollars on logo designs that will never be used.
For months I’ve only been watching SBS On-Demand but there has been a definite increase in advertisements, which does interrupt one’s absorbtion in whatever the program is.
The new SBS website doesn’t work with ad blockers and tracking supression turned on. That was the official explanation when I comained that it wasn’t working. Shame on them.
Why all the NAZI worship?
I am completely fed up with the endless and mindless promos, and repetitive mindless advertising.
SBS is a commercial channel in disguise and is conning the taxpayer
I never watch commercial TV because of the frequency and loudness of the advertisements. SBS is now nearly as bad, and hence I rarely watch it any more. As others have said, advertising gambling is particularly egregious.
absolutely far too many ads and breaks on SBS. The number of commercial breaks are more than frustrating – they are off-putting. Does anyone at SBS have a clue how disturbing these ads are ? put the ads in at the end or the beginning but not disjointed and all over the place. We are watching less of SBS because of these off putting ads and breaks – it‘s just about unwatchable now more than ever.
Far too many ads. It is not uncommon for precisely the same ad to be played twice in a row. Ad breaks can occur in the middle of an important plot development, or even in the middle of a conversation, abruptly interrupting the flow of a program. There are far too many ads for gambling, life insurance, funeral insurance and pay day loans.
I/we like watching the programs on SBS, but, there are so many ads on live SBS and during programs on SBS that are spoiling a very good organisation. The gambling ad promotions are particularly annoying and should be removed. The SBS programs are ruined by frequent and inappropriately timed ads. In some European countries, they run advertisements between programs only. SBS management should consider this method of presenting advertisements.
SBS is a public broadcasting service – why should it be allowed to have ANY advertisements? In our view its programs are on average much more interesting than those on the ABC, as well as being better directed towards Australia’s multicultural community. Why spoil this reputation with inserted garbage? The Federal Government should increase its support of SBS so that program excellence can be maintained without the detracting advertisements.
in addition, the ads frequently ‘break’ the programme, by getting hung right when they end, which means I have to refresh, then watch the entire ads segment AGAIN, after whichis sometimes hangs for a second time. It is just so frustrating having ads ruin a show.
It is not just the ads for commercial products, which are repeated ad nauseam – especially for NAB – but the repetition of ads for SBS’s own programs and station idents. To add insult to injury, some ad breaks are for many products over several minutes, whereas another break might be for just one station promo. Especially irritating is trying to watch movies on SBS World Movies. It should be remembered that this is a public broadcaster. Shame on its management.
SBS has a proud history of reflecting the Australian multicultural community. Unfortunately in recent years it has rather debased itself with the degree of commercial derived income it has chosen to generate. While I accept that funding has to come from somewhere, SBS should not have been left by various governments to fend for itself. I believe that a multicultural national broadcaster enriches and sustains our diverse democracy.
Elimination of all ads from SBS is my preference
SBS must reduce (preferably remove) advertising during each advertised programme.
SBS Movies should not allow breaks in the programme. If it must show advertisements, do so only at the end of a programme. By the way, will SBS Movies stop interrupting the final credits by sharing the screen with the upcoming programme – we know what that will be anyway.
These days, we really can’t watch SBS live – we just record everthing and watch it later.
SBS should be properly funded to operate without advertising. It is actually quite a small amount out of the national budget.
The purpose of the SBS is not to make money but to support Australian society at all levels.
Ditch all ads.
Too much advertising – too much that is unethical! Some would like to pay – let them – as a voluntary service. But get rid if all advertising or have it positioned entirely at the end of the program where viewers can use the time to go and make a coffee. I enjoy NITV – keep all advertising if on that channel public service announcements and to do with Indigenous corporations and businesses – wholly subsidised by any companies doing business on First Nations country – and as for SBS – only in one clump at the conclusion of programs. Get rid of any SBS Board member connected with any LNP politician – or of any PM or Minister appointment.
Who’s working at SBS to make Murdoch happy?
SBS was our go to channel with great content and in addition to ABC was not interrupted and not Americanised in content or investing in profits before people. It has recently slipped into sameness in programming and ad intervals.
We mourn the decline.
SBS is being destroyed by ads.
In particular by ads that interrupt programs.
Too many promos, too many ads make us never buy any of the goods or services advertised and never watch the over promoted programmes.
Also the adverts interrupt the flow of the program which disrupts the viewer’s enjoyment of it. Plus the same adverts are shown repeatedly through the length of that program.
If adverts are really necessary then just show them between programs.
Never watch SBS live anymore. Record programmes and fast forward through ads. Therefore was not aware of the proliferation of gambling ads but object to their presence because of the social harm inflicted on vulnerable gamblers.
Like others we record SBS programs so that we can speed through the excessive adds. Content overall is good. If SBS were to run fewer adds it could delete the less ethical adds, including getting rid of funeral insurance adds – which are just a great scam.
I am one who dislikes much about the advertising industry in principle. That’s another discussion, but the result is I watch less SBS programming than I used to in the pre-ad days when SBS was much closer to the promise of excellence than it has been for many long years. And, like others have stated, what I do watch is almost exclusively recorded to enable the ads to be skipped. A habit I do admit, I employ across free to air TV in general, not just SBS. Excepting the ABC of course, the only option remaining one can enjoy watching live, that is until our gracious Federal Government destroys that too.
excessive program preview and announcements along side commercial advertising purporting to help or benefit us are at best misleading and at worse plain wrong. We end up paying when advertising cost are added to service and goods from these organisations.
So many ads and promos spoils the programme flow, especially with broadcasts of cycling.
I remembr when you could watch a whole program without a break in it. Adverts inbetween programs is much more acceptable
Like most here I am a passionate sbs viewer. Like most here I find the repeated and excessive advertising insulting. I am smart enough to get 5he message once…. I now record sbs so I don’t have 5o endure the advertising. If 8 wanted advertising I would watch commercial television. Enough!
The constant repetitious promos are becoming as annoying as the constant repetition of unconvincing ads.The content of the program needs to be very good to tolerate incessant interruption. Watching SBS used to be a relaxed affair.
Can’t watch the commercial channels as the ads drive me wild. Our wonderful leaders have cut the ABC’s budget to the bone so they can’t make many interesting programs anymore and can’t fill the program schedule with anything other than repeats – which leaves SBS. There are too many ads on the channel (one is too many) but I can still put up with them (just) because the channel content is so much better than the other offerings.
Obviously SBS needs to generate funds from advertising but wouldn’t it be good if it could give itself a point of difference by concentrating on getting advertising from companies with good ESG policies and sustainable products and services. That way we would see the back of the gambling ads and Coles pushing rubbishy little plastic toys to shoppers kids. Instead we would hear from companies whose products and services the SBS community might not know about but actually want to buy.
There should not be any advertising on SBS it is a public service and the need for advertising revenue is forcing SBS to take more and more middle ground to attract the advertisers
SBS needs proper government funding
SBS is a not-for-profit public service broadcaster with its own special remit. It complements the ABC and should be fully funded by government, as it was at the outset. Starving SBS of funds and forcing it to raise advertising revenue undermines SBS’s role.
Because ads ruin all viewing but particularly excellent drama, we NEVER watch SBS live any more but record and watch later so we can fast forward all interuptions.
This is so disruptive that hardly ever bother watching any SBS programs which is a great loss and sadness as SBS used to be our favourite and most important TV channel.
Reduce the amount of commercial ads / commercial breaks on SBS. !!!
I used to be an avid SBS watcher but haven’t watched it since the ads started. Great programs – but the ads are disruptive nonsense that make me hostile to whatever the ad is about and to the organisation doing the advertising.
With no ads I’d be back in a flash.
In a world that is a wash with advertising and insidious messaging it was a joy to have channels such as SBS and ABC that were informative, had no distractions(advertising) and you could be sure there were no hidden agendas, such as commercial interests. Being able to watch any programme with out interruption, I find, means I am able to absorb and digest the content and enjoy and understand it more. A country as fabulously rich as ours does not have to sell space on its informative, educational networks, they are not there to fit into a ‘market economy’.Their purpose is not to fill the public purse but to inform, educate, provide the arts and connect us.
WE WILL NOT ABANDON SBS TO NEO-LIBERALISM – ROLL ON THE NEXT ELECTION
I look forward to the Tour de France every year but dread the Skoda adverts
SBS overdoes the promos. I get sick of seeing the same ones over and over again, so a good start would be for them to cut back on promos. Next, if they absolutely have to run any ads or promotions they ought to be between programs, rather than create jarring interruptions within the programs themselves.
The public was “sold” on the idea of SBS running ads when we were told that they would occur only during natural breaks. That certainly isn’t the case today.
I used to love watching SBS live but now I only use the On Demand service as the ad content on the live shows is excessive. I find that two ads occasionally on the On Demand service is fair and reasonable. i sincerely hope that the live shows can return to what they were and get my support again
ABC and SBS are both guilty. ABC flogs its program offerings so much I feel disinclined to keep the tv on. As for SBS it is putting ads and promos ad nauseum – reaching the depth of dregs when advertising gambling. Again, I tend to turn the tv off and the radio or cd player on. It is amazing how one can get used to the tv off when totally tiring of ads on our public broadcasters.
We love SBS but often we stop watching because there are far too many ads. It’s just so disruptive and not what you expect from such a channel.
The content of the programs are good but Ads of 5 min each are very disruptive and disappointing
I barely bother watching SBS anymore purely because of the number of ads! I used to watch only SBS and ABC for ever, but now it is just ABC or i go to Netflix or Stan. I cannot stand watching ads. Most of the ads on SBS are promos for SBS. Why???
The ads and their frequency are ruining SBS television viewing. It is up to everyone to pressure their federal MP to commit to properly fund SBS AND THE ABC. The voters should pressure the ALP to promise proper funding of SBS and the ABC if they are returned to power.
I’ve always loved SBS because of its high quality programs, but am definitely not enjoying the growing numbers of ads interrupting my viewing.
Yes I enjoy many of the excellent docos on SBS but do not enjoy the many breaks
SBS is spending this ad income on programs. So if we insist on fewer ads we will have fewer worthwhile programs.
Surely we have to campaign for more government support for the SBS. And we have to accept that this means.higher taxes for people like us.
Or we can have another 7, 9 or 10 without extra taxes but with lots more even more awful ads (and demeaning and exploitative programs).
Ad breaks seem to be placed in a way that breaks up the story line in many dramas. Also, there are too many ads which occur too often.
Sometimes an ad just misses the end of a scene, coming in too early, so that a tiny bit of the scene plays after the ad break.
SBS will kill off its audience if there are too many repetitive ads. And as for gambling ads, they are really sinister, a social evil, completely at odds with the benevolent, unifying charter of SBS. Why do evil while doing good?
We now never watch sbs live but record and watch so we can skip ads and promos. Also we never use sbs on demand because they do not allow fast forwarding of ads. It’s a shame as were regular watchers of sbs but now hardly ever view.
Ads just so ruinous to intelligent, impartial, informative broadcasting. It’s as though SBS has sold its soul and watching it with so many horrible commercial breaks is just so soul destroying to the attentive viewer.
The number of ads and promos seem to be constantly increasing.
Most ads are idiotic and appear to target the simple minded eg. Real Insurance, NAB, Youi, Car Insurance with flying dragons and other crap (made such an impression that I can’t remember the company name). In fact I would refuse to buy from any of these companies even if there were $ giveaways. If they want to waste their money, show them on commercial TV, 7, 9 10
Save SBS from commercialization!!
There are also too many – very repetitious- ads on SBS on Demand.
I watch SBS less than I normally would because of the ads. When I do watch I generally record the programme and fast forward through the ads.
Let’s make our SBS completely ad free again, to reduce corporate influence on the SBS, and thus get an information source that is less distorted by the economic and political agenda of rich people.
Far to many ads, repetitious ads very annoying and break up the story line. Gambling ads do not have a place on SBS at all. I really enjoy the programming but the frequency of the ads are dreadful.
SBS has great content. If the ads were limited to the beginning and end of programs SBS would have a much greater audience, so more people would see the ads. But not ads for gambling please! Also what is the point of interrupting a fine program with a promo? It must be counter-productive.
SBS used to be my favourite channel. Now I hardly ever watch it. The ads are so intrusive I lose track of the program I’m watching.Shame!
My preference is for full public funding and no ads, but if we can’t get rid of them one ad-break every 30 minutes and no repeating the same ad in a break, please.
I’m one of those who prefer to record programs and fast-forward through the ads, but if forced to watch an ad, I add the advertiser to my list of businesses with which i will not deal. If many people did this, and let the advertisers know that their ads are counterproductive, we might have to endure fewer of them
.
Advertising ruins unity and flow of programs to the extent we largely record and fast forward through ads or we are increasingly not bothering and this means we risk missing so many unexpected viewing delights, which have always been one of the great pleasures of SBS.
Also, too often little thought seems to be put into placement of ads with some really frustrating and irritating interruptions.
Oh, and below its ‘maths’ not ‘math’ if we are to try to be Australians and not Americans for just a little bit longer
SBS demoted itself in my mental hierarchy of TV stations when it embraced advertising. It slipped to the rank of the commercial stations which I watch only if there is nothing I want to watch on ABC stations. It also in my mind largely lost its role as a community leader with an ethical and an educational function, even though I had initially welcomed it as such. This was particularly the case when it decided to accept advertisements for gambling.
Is there no other model of public funding, such as that offered by the Public Broadcasting System in the USA, that could redeem the detdriorating reputation of SBS?
The root of the problem we experience with ad breaks, malaprop content, forced viewing of promos on SBS [latterly on ABC also], is simply that our federal government, its owner and operator, no longer believes in the guiding principles of FTA community minded TV. That is to say that overtly, this government has given up supporting a multicultural, fair minded and open society, that attempts to educate the receptive. It is done with it and especially with the EXPENSE.
Commercial broadcasting (advertising) belongs on commercial networks.
SBS like the ABC is a publicly funded network and should not be required to run advertising at all.
Promoting its own programs and carrying any public service announcements deemed by governments to be in the public interest e.g. fire warnings, pandemic or other public health emergency announcements is reasonable, but running promotional material for gambling and other product advertising is not. Indeed carrying commercial messages would often be highly confusing to some SBS multi-cultural audiences new to our country. People wishing to be told what to buy by marketing ‘professionals’ can surely find more than adequate satisfaction from the many opt-in commercial radio and TV channels that actually dominate the airwaves throughout Australia.
I used to watch SBS almost exclusively, now I just watch the news then turn the TV off because there are too many adds
It’s unbearable to have programmes interrupted by commercials at any time.
I agree with the majority of comment here incl Tony G in that like him I used to watch a reasonable amount of SBS.
Now my viewing time is probably 5-10% SBS vs 85-90% ABC.
All due to the disjointed viewing experience of current SBS programs with many forced program breaks due to ads & promos.
As a public broadcaster it should be fully govt funded!
As the Govt has cut the funding to SBS they have been forced into taking ads. Rather than breaking up the program it would be better to run a block before each program. The allowable number of ads could then be evenly spread through out the night.
It’s the endless self-promos that do my head in. (ABC is the same – worse!) Totally disinclined to watch upcoming programs because I feel like I’ve seen it already before it is even broadcast. They’re relentless. Pity. Generally speaking, programming is quality content.
I cannot describe the annoyance I feel when watching SBS. The content is often ruined by ad breaks at critical moments. Ads should not be on SBS full stop! And the highly commercial nature of the ads is appalling. If I wanted to watch commercials I watch commercial TV. Please remove these ads from SBS or at least put them at the beginning or end of programs.
It used to be that the ads were at the beginning or end of a program, which was fine.
Now, it’s often unbearable: it doesn’t matter with food and cooking shows, but it’s ruining films and TV series.
And the way they run 1,2,3,4, promos for their own programs, over and over and over again, is infuriating because they’re not even making money out of it, they’re just being annoying.
It will be interesting to see if community pressure makes any difference. Getting adequate funding for the ABC hasn’t had any luck…
It’s not only the number of ads and promos interrupting so many excellent SBS programs ncluding those on demand, but also the repetition of the same ads, often in the same bracket. very irritating to watch so many really stupid, puerile messages.
I would still rather watch SBS than commercial channels.
I believe SBS should be ad free as it is a multi cultural channel serving many communities. I totally disagree with gambling ads as they destroy families stripping them of money to supply necessities. Please keep SBS ad free. This is the first step to totally destroy the channel when the ads take over people wont watch the channel which is very sad. ts
There are too many advertisements on SBS.
In most respects there is nothing to distiguish SBS from the present commercial channels. The ads. and promos. are both a nuisance and distraction from the program and frequently are repetitive to the point that it appears they are run simply to fill ad. time in the program. Given SBS low viewer numbers I doubt that the advertiser pays “market” rates and it appears that the ads are run repetitively to increase the revenue earned.
Promos are similarly nuisances and amount to “stuffing” to ensure program run time fits the program for the day/night.
I have give up SBS because of these aspects of its operation which are an insult to viewers and taxpayers.
I’ve stopped watching some SBS programs because there were so many ads it made enjoying the program impossible. There is a lot on SBS I’d love to watch but I don’t because of the excessive advertising.
I am watching SBS less due to the adverts
The Government should properly fund SBS so that it’s not forced to play ads. TV advertisements destroy the enjoyment of watching shows and the flow of the program you’re viewing.
‘
I now watch ABC and Netflix only because of the increase in SBS advertising
the frequent, and sometimes repetitive ads make viewing of programs very frustrating. I can cope with advertisements and promos at the beginning and end of the programs, but I almost give up watching when my viewing is fragmented and disturbed with constant ad breaks. My loyalty to SBS is fraying!
Sadly, many of the ads on SBS are of the same character as the ads on commercial television :-( I very rarely watch commercial television, in many ways because of the excessive and blatant nature of the ads themselves!! There is no room on SBS for crass advertising. There should be strong ethical and quality standards for all advertising on SBS.
Grossly inadequate government funding equals far too many ads.
This almost certainly equals smaller & more disillusioned audiences,leading to still more irritating programme promos. It is incrementally self-defeating, and a far cry from the wonderful ad-free channel that was SBS when it began. There was nothing like it in the world.
What can be done?
Bravo to the Friends for instigating this research. If we have to have ads – and how stunning it would be to abolish them – I support a campaign to return them to the front and back of programmes only. And let’s join GetUp’s mass campaign to restore adequate funding to the ABC and SBS – our two most important cultural institutions.
Advertising undermines SBS’s integrity and the quality of its programming.
It is inappropriate for a public broadcaster to have to rely on advertising to supplement ever diminishing government funding (I might add that in a climate where the share of advertising revenue increasingly goes to online and social media, it also disadvantages the commercial broadcasters, causing loss of quality in programming, loss of inecentive to make quality pprograms and loss of jobs in tge industry).
I agree with all the comments above!
The Promos are almost more annoying than ads; so frequent and repetitious. As a SBS viewer I generally know what’s coming or I can easily check elsewhere. Enjoying less and watching less
I believe thaat it is so important to keep this very informative TV station which provides first rate programs.
I very much agree with what Gayle Davies has said above. As annoying as the interruptions are, what REALLY concerns me is the use of commercial sponsorship on SBS in the first place and the inevitable impact that it has on what should have remained a ‘public’ broadcaster!
The frequent ads on the SBS News are very disruptive and break the continuity of a high standard news service.
Please don’t let SBS turn into Channel 7…or 9…or 10……
Your loyal audience does want to know what’s new and upcoming, but not at the cost of uninterrupted programming. Promos fine, but just at the beginning of the evening. No more ads please……
I have stopped watching sbs movies and find the breaks in cooking shows really annoying!
please take note!
Yes I think excessive advertising undermines SBS’s valuable multicultural service. I object also to the excessive budget cuts of SBS. Australia is increasingly a multi_lingual society and needs SBS, which provides quality news movies docs etc in many languages.
I love SBS shows but unfortunately they are interrupted by apparently more advertising than they are legally permitted.
Come on SBS – you used to be a publicly funded, ad free, media. I know you have had cuts in your government funding but please keep the ads & promos to their legal length
The 5 minutes per hour of ads should be between programs.
Ads between programs rather than during…is this possible?
SBS1 is shooting itself in the foot as far as I am concerned as I record their programmes in order to fast-forward over their far-too-numerous ads.
I mainly watch SBS and the ABC.
I hate the SBS’s useless excessive promos.
The migration of advertising revenue from television to social media must be making it harder for public broadcasters like SBS to get top dollar for their ad slots, and I guess it forces them to stuff the programming with more and more ads, repeated over and over again. Younger people dont watch television very much any more, but use social media for their news and commentary and Netflix and the like for movies. Maybe a new model needs to emerge, where SBS could get a new lease of life by removing advertising altogether and buying slots on social media to promote their content, much of which is in fact extremely well matched with under 40’s with weblinks embedded to allow rapid downloads and switching between the media. Just thinking aloud but maybe there should be some serious think-tanks which fans of SBS could participate in to find a middle way which will keep the fabulous programming of SBS going while feeding it into other online media.
With the Prime Minister having taken over ABC TV as if it was his own pulpit, we watch a great deal more of SBS than ever before. As we both hate advertising and with the advent of continuous gambling advertising on the commercial channels, SBS along with On Demand and iView, plus DVD’s has become our entertainment during Covid19. I love the ABC as it was prior to the election of the present government, which is Murdock inspired and has the decimation of the ABC a priority. I wish we could get it back to its glory, with really excellent drama, comedy and news and current affairs. During the recent bush fires it was a life saver (as it always is during any emergencies. Since moving from Queensland to Victoria we have swapped cyclone watches for bushfire and polluted air warnings, plus flood warning during winter. Gardening Australia is one of our favourite programs plus the English dramas. Please leave both SBS and ABC alone, restore the refunding. Use the next two politicians salary increase to add to the funding.
The content on SBS is way ahead of commercial tv but the ads bring it back to the field personally we turn the volume either down or off when the ads come on so from an advertisers point of view it is a waste of money.
Where is the watchdog? Who is checking up on SBS? Is the Board aware? What are they doing about these breaches? Too many questions, not enough answers!
The SBS is not like channels 9, 10 or 7. Currently there are too many ad breaks that interfere with programme content, particularly the news. There should be no ‘cash cow’ moments jumping across the screen. This fabulous channel could certainly do with less of the ad stuff.
As a teacher of media, film and communications, it is alarming to see the quality of SBS programming, especially news and current affairs decline. The Special Broadcasting Service Act established in 1991 was to serve our multi-cultural communities, and have limited advertising and sponsorship of programs, which has been unique in addressing cultural diversity in Australia. Australian tax payers deserve better than been subjected to gambling and fast food ads. It comes down to policy and regulation. What is the Australian Communications and Media Authority doing about this issue? Another example of the ‘toothless tiger’ scenario?
Yes ads really kill SBS – which has such quality programmes. WE get enough ads in other commercial channels and it is pretty bad the ads just take over and one barely gets a straight run at the porgrammes.So much time is wasted on these ads – all I want is to see a proper programme and a minimum of ads if they have to be included – not the other way round. I guess it boils down to ‘money’ to run the shows…but SBS is a crucial channel specially for our multicultural folk – and apart from that everyone for that matter. WE need cultural diversity and more of it.
I watched some french movies on SBS a few weeks back. It followed the commercial channels by increasing the frequency
of the ads towards the end of the movie.
This spoils the atmosphere and tension build up of a piece of art.
I once went to a video store , hired the movie on a commercial channel , watched the movie , took the movie back and got home well before the TV movie finished.
Have never watched a commercial channel movie since (in the late 90s).
I now buy my French movies and don’t intend to watch a TV movie on SBS again.
A mid movie break of a few ads, is tolerable(
Short attentions spans indoctrinated into the populace gives any country all the advantages of US culture! (sarcasm)
During part of the highlight broadcast of the Tour de France on Monday I’m sure that there was more advertising time than program. Its just exasperating. And the gambling advertisements are just an embarrassment – Australia is better than this. SBS On Demand has many very good programs, but the advertising continues even there with the same advertisement often repeated twice in succession. Its just insulting. We need a government with the integrity to resist the predations of Murdoch and restore the funding of the National Broadcasters. This government’s unrelenting victimisation of the ABC & SBS and their journalists betrays not only a subservience to Murdoch, but also their recognition that they can’t tolerate their actions being exposed to public scrutiny.
It would be soo nice to do away with ads!
The excessive ads and promos are especially galling during the current TDF coverage, where some ads seem to appear in *every* break, multiple times per hour for the entire three weeks. Repeatedly seeing the same ad I wasn’t interested in the first time only aggravates me, and inclines me towards boycotting that advertiser; I have a good memory.
There are so many breaks if I directly watch a film on SBS it encourages me to record it. Then I know I can fast forward through all the interminable promo repeats and ads and get the continuity any decent film deserves. It certainly seems the interruptions have become more frequent and last longer than they used to.
If the ads are so essential maybe SBS could choose to cut down on the huge amount of time taken up with promo repetitions. You get the feeling sometimes SBS is trying to hammer their programming plans into our heads!! Unnecessary, and almost insulting.
I value SBS greatly, but this aspect of their programming tends to turn me off. That is sad.
It should not be permitted to repeat an ad in less than 10 minutes.
I value SBS
In program ads are becoming intolerable to the point where I switch off
I am no alone
I stopped watching SBS years ago, once they started having in-program ads. Until then it was a wonderful part of my life.
I would love to come back as a viewer, but won’t as long as there are ads within programs.
We don’t watch any commercial stations because of ads and no longer watch SBS much for the same reason.
I was happy when the World Movies channel came on free to air but was devastated when I realised that it too was subjected to frequent ad and promo breaks.
I compare that to paying to go to the cinema to find that the movie is constantly interrupted with ads. The audience would just walk out.
This is what SBS is doing: charging you (through taxes) to see a movie and then putting ads in it. Surely SBS must realise that their audience is walking out too.
I’m shocked at the ads inserted into movies both on World Movies and SBS on Demand. You can’t fast forward. Certainly a disincentive to watch. SBS should be public service TV or at least just carry ads between programs.
I have learned to use the mute button and have something else to do so I can avoid the ads. They are so inappropriate.
Good programs ruined by excessive ads and promos. You’re losing your audience SBS.
I have nothing to add to what I indicated. Let us not allow SBS to become the mouth-piece of a
corporate-porno-neo/liberal-proto/fascist regime.
Thank you for the opportunity to whisper my view.
Vive la republique !
SBS has great programs, especially the documentaries. They should restrict promos to be shown only in between programs, and time the paid advertising better, especially prevent ads to be shown twice in the same break, as I’ve seen happening.
I don’t watch commercial stations, ABC is my other station who still has no commercials.
I understand the need for paid commercials on SBS, but please make it less intrusive.
The ads put me off watching SBS. I prefer to download their programs and thus avoid the ads.
Assuming the revenue from ads will improve the quality of programming rather than rises for executives, I don’t disapprove of advertising. But reduce the number of ads and the frequency of programme interruptions, rise above the commercial channels, give us the public more reason to tune in to SBS instead of other channels.
It’s obvious that the Liberal Party is trying to silence SBS just like they are the ABC by reducing funding. In order to make up the shortfall SBS is resorting to excessive advertising (and more promos because they can’t afford to buy shows to fill up the time). This is of course reducing the number of viewers which is exactly what the Liberal Party wants, because they can then use this as an excuse to eventually shut it down altogether.
Too many ads, which also indirectly has the effect of censoring content that may be critical of advertisers. Get ads off SBS.
The adds put me off watching SBS programs. The add breaks all seem excessively long. So many interruptions make programs disjointed. They also make movies excessively long.
I used to love watching SBS because of the quality content and very few ads. The ads that were shown were usually really interesting, creative ads too.
It’s very disappointing to see SBS lowering its standard and so I would rather watch movies on Netflix now.
On tonight’s episode of Great Asian railway journeys, SBS ran a promo during Michael Portillo’s wrap. The credits hadn’t begun! The SBS voice-over blocked MP. It was very annoying.
The next-program sound promos are always annoying when they run while a program is still screening. The visual promos before the end of films, when they take up a third of the screen and compress the credits, make it very difficult to read the credits. I don’t understand why they interfere with the film. It is annoying.
The SBS like the ABC are public broadcasters and neither should have any commercials. Let alone go above what has been allowed to the SBS. The solution is surely to fund better this unique TV station that has and is crucial to the cultural diversity and with it, social peace Australia has achieved.
The SBS like the ABC are public broadcasters and neither should have any commercials. Let alone go above what has been allowed to the SBS. The solution is surely to fund better this unique TV station that has and is crucial to the cultural diversity and with it, social peace Australia has achieved. I stand behind any movement that aims at preserving our public TVs
Most people don’t want to up taxes, so government funding will continue to be hard to get. Advertising is one of the few options SBS management has of securing some revenue to fund their excellent services. The advertisers would rightly want their ads aired during a program to ensure it is seen. As many people have commented, the promotion of other programs is an annoyance that could be reduced by running them only at the end of a show and to fill in any time shortfall to the start of the next program in the hour/half hour. Doesn’t seem too hard to do. Otherwise, great service, SBS
I agree with Peter Alabaster’s comments completely.
No gambling ads please. It is such a national disgrace that gambling companies take money from unfortunate gambling addicts. Advertising them is almost a crime itself.
It’s the government which forced SBS to show ads in the first place. I guess they have to pay for their pensions – $43,700,000 paid in 2019. https://williamsummers.blog/2019/03/15/the-truth-about-parliamentary-pensions/
SBS is becoming unwatchable due to the frequency of ad breaks and the number and length of ads in each ad break. So many times I have just turned off due to ads. I NEVER watch commercial TV channels due to ads (7, 9, 10, etc). Please don’t force me to add SBS to that list.
Gambling Ads have to stop – so destructive for gambling addicts.
We stopped watching most SBS programs, except evening news, because of multiple Ads and annoying breaks. Used to love so many of the SBS programs.
Not only are increasing ad breaks strangling the SBS like poison ivy, but there is far less diversity of content and international input than when I first watched in the ’80’s. Then you could enjoy pioneering features from anywhere in the world. Coming as I did from the monoculture of the BBC, it seemed like the air of another planet. Now the programming is overwhelmingly European, with a disproportionate amount from Scandinavia.
Elsewhere there is an over-emphasis on sport, and on history features on a National Geographic level. This happens when special interests from the corporate world spread their slime over a good initiative.
Also note that there are are ad breaks during “SBS ON Demand” streams. These ad breaks often break the stream so that you have to restart the stream in the browser just to be able to see the rest of the program. The fault occurs on all browsers. It is not possible to tell whether the fault is in a specific local PC setting or if it originates on the server end. One would think that by now (in 2020) being able to just see the program would be the default.
As an enthusiastic SBS viewer (particularly Nordic Noir) I find that unnecessary ad breaks lead to a very disjointed, and at times very annoying programme.They totally disrupt the rhythm and continuity of at times, gripping programmes.
I find the same ad repeated multiple times per program off putting and makes me think twice about watching the program. It would be good to be able to watch the great movies on offer without the ads. I find some ads, such as the gambling ads, disappointing.
The more they go down the path of funding the service with ads, the more government funding will be cut.
Ads should inform viewers about a product, not brainwash them. Showing the same ad multiple times during one program feels like the latter. PLEASE get rid of gambling ads!
Far too many ads full stop, but the gambling ads should be removed altogether. Also, the ads in programs streamed on SBS On Demand always seem to be placed fractionally before the end of a scene.
The number of Ads has been increasing and the number shown one after the other just makes you mute and walk away therefor not watching them anyway. I especially resent gambling advertisements on any station because of the damage gambling does in the community, but for them to be allowed to use a public broadcaster to peddle their immoral business is worse.
I try to avoid ads in placing the TV channel on ‘mute’. However, this means that I often miss out on the beginning of the next section of the actual program. This is very annoying. Therefore, get rid of as many ads as you can and do not repeat on ad over and over again.
We have always valued SBS as offering a diverse balance to viewing and relished the breadth and depth of material available. We understood the funding measures that gave rise to ads first appearing and accepted them because they were kept between programmes. Lately, however, the intrusive interruption of good programmes makes them almost impossible to watch. It’s also insulting to the integrity of the original programme-makers. I am now very torn between supporting SBS and turning it off altogether.
I guess I’ve gotten used to it. It’s the same as all the commercial channels.
I have stopped watching SBS because of the volumne of advertising which I think is over the top.
repetitive, boring, on par with commercial television stations. defineately more ads than five minutes per hour at peak popular times. one has to ask why SBS can be allowed to break their charter.
I love SBS for it’s quality programming and world view. It’s public broadcaster and should not have ads. I will continue to watch and support SBS but refuse to watch the ads impose upon it so now I record my programs and fast forward through them.
It appear to me in the last few years has become an appendix of the BBC
So Much for a multicultural Network ??? very disappointed … In the 80th I was part of push to establish this network
SBS used to be my main source of world news, world films and Australian matter. All the advertisements and promotions now interrupt the viewing and irritate me, so regretfully I have largely stopped watching SBS. It was better when ads were kept to the end of a program (when one could wander off to the bathroom or make one’s next cuppa before returning for the next program without missing anything.) What SBS really needs is an increase in Government funding so that programs do not have to be interrupted.
There are just too many ads including gambling ads. SBS must be properly funded to avoid this.
The ads on sbs ondemand not only break into the program but occasional fail to load quickly so that the time of the ad break is extended and a couple of times the stream has completely frozen and meant having to leave the app and rejoin.
And even worse they are starting to not keep to their advertised schedule and running one program into next time slot just like commercial stations which are atrocious
Commercials are designed as interrupters and as such contribute nothing to the seamless enjoyment and understanding of quality program content such as SBS has traditionally made available. SBS today does not uphold the true role of a public broadcaster a result of a previous ideologically driven management team’s decisions and a conservative government with a genuine fear of an informed, enquiring public mind.
I have stopped watching many of the programs on SBS because of the excessive advertising.
I don’t watch commercial TV. SBS has joined their ranks.
I’ve stopped watching SBS and SBS on Demand due to the ridiculous amount of Advertisements which are disruptive to the show. My now choice is the ABC and I’m prepared to forego the great series that SBS televise due to this.
With some ads repeated multiple times in the one break, they really have gone over the top!
What a shame that a public network, set up with high cultural ideals has been discredited by governments and has to rely on crass commercialism. Any and every program is interrupted by ‘ad breaks’. These impositions turn off engagement and therefore turn me off SBS.
I wrote a letter only this week regarding the excessive promos and advertising on SBS, as I felt angry enough to do so. All of the above comments re-iterate what I wrote, the program ‘The Salisbury Poisonings’ was entirely spoilt by the oft-interruption of mindless promos, followed by the same advertisements over and over again, that it was hard to keep track of the plot.
Far too many ads,and NO gambling ads.
The only way I can watch SBS these days is to tape it and fast forward through the ads. Even the news is painful to watch. Who would have thought that such a brilliant TV channel could be ruined so thoroughly.
The only way I can watch SBS these days is to tape it and fast forward through the ads. Even the news is painful to watch. Who would have thought that such a brilliant TV channel could be so thoroughly ruined.
If SBS must raise revenue from commercials, due to a short fall in funding, then those commercials should be top and tail of programmes, and not within a programme.
Excessive advertising creating disjointed programing. Increase SBS funding to eleiminate ALL ads!
Like many others I watch a lot less SBS than I would if they didn’t interrupt programmes for ads, eg I turn the news off at the first ad break. If SBS listened to its audience and went back to showing ads only between programs I am sure their audience numbers would sky-rocket. And don’t higher audience numbers mean higher revenue from advertising?
I have noticed that recently there are many more ads in On Demand programs and they regularly break into the program at an unnatural moment, sometimes even cutting in in the middle of a sentence.
Many ads occur more than once in one ad break.
There should be a greater level of government (i.e. taxpayer) money invested in SBS so that less ads are needed on SBS (especially gambling and fast food ads).
I will not be watching SBS On Demand and will be watching much less SBS television because of the grossly excessive number of advertisements and self-promotion ads.
Other than much of the otherwise great content, one of the main reasons I used to watch SBS was for the lack of ads. It seems to be slowly turning in to just another commercial television station like 7, 9 & 10. Of late, it has gotten to the point where I watch very little of free-to-air TV anymore. The dumbing down of modern society continues unabated and everything is becoming nothing more than a buck in someone else’s pocket. Please don’t allow this to happen to one of last vestiges of decent television or I’ll be gone for good.
Whilst the content can be very good on SBS on demand, a frustrating aspect of watching has been the repetition of promos, often the identical promo played four times in succession in a single ad break. Also, the ads can take a while to load, or freeze all together, and we have to log in again. In addition, I object to the sudden very loud volume for some ads.
SBS has some great programmes which i have mostly watch on catch up but I am finding the ads intrusive and off-putting to the extent where I often decide to watch programs on the ABC or Netflix. Originally SBS showed ads at the start and end of programs which was reasonable, now they continually intrude into programs and disrupt the viewing experience.
If it were not for the incredible financial pressures, lobbying and coercion just upon our Federal Government by the Murdoch media Groups and the other major media corporations that wish to have either the ABC and SBS privatised or disenfranchised so they are completely hobbled thus vastly inhibiting their influence and effect within the Australian Media and in providing unbiased and honest journalism and content. It is a matter of who is controlling our Government, and it is definitely not the people these days.
On the point of giving up on SBS. One might as well watch commercial channels – but no thanks! Funding cuts – overload of promotions – insufferable advertising.
Any decent TV viewing destroyed.
The best strategy is to take note of who is disrupting the programming on SBS and never do business with them. My shadow shall never darken the door of Chemists Warehouse, whatever that might be. The only problem is the ridiculous number of house ads. Why do they do it? Someone in the SBS hierarchy obviously has a vested interest in making the viewing experience as annoying as possible.
Wow. My sentiments a million times over! Could we please get details of the ad removing app mentioned by Peter Huber. I didn’t know such a thing was possible. Like most people nowadays we too record all programs for replay and fast forwarding. But it’s still annoying, and easy to fast forward too far and have to backtrack. Gough Whitlam implemented some excellent ideas during his prime ministership, but abolishing the radio/tv licence wasn’t one of them. I would be very happy to pay a levy if it meant no more ads! I think the BBC is still funded from licence fees.
P.S. It’s “simple MathS”. We already have too many American programmes on TV, let’s not let it interfere with our language as well!
Like many others we prefer to record the many SBS programs and watch them later and skipping the ads. I would sooner pay a license fee for ABC and SBS than have ads.
The Federal Government is relentlessly reducing funding to ABC and SBS. For SBS, having a reasonable number of ads provides ongoing funding to pay for excellent, varied programming, including innovative productions. By all means, keep the ads as ethical as possible, which means excluding gambling ads for instance. Please, though, allow monies to keep coming in.
I am shocked by the extent of advertising, in particular gambling advertising stealing its way into SBS. I also find sudden decibel explosions with ads are actually very distressing , I would have thought counterproductive to their effectiveness . I fear the bad guys are winning though, and public broadcasting is under unrelenting threat. Interesting that James Murdoch, however has in the end defected from News ‘bring down democracy’ Corp . Is there hope?
RESTORE ITS ITEGRITY
RESTORE ITS INTEGRITY
SBS offers some wonderful programmes, of artistic merit. The frequent interruption with commercials spoils the continuity which is an important part of appreciating the work of art which they represent.
Return to all ads at start or finish of program.
SBS on Demand has the absolute worst commercial breaks imaginable. They’re made even worse by the clunky cuts and reintros.
Agree with almost all comments re much too frequent, lengthy, inappropriately spaced, repetitive ads AND promos (especially when there are 2+ in a row of the same thing). This is particularly annoying if following a series and watching more than one episode in a row. Often I find I might be interested in a promoted program but after the repetition of the promos I could never watch the program as the promos have driven me crazy.
I mostly watch SBS On Demand and the ads often interrupt a scene, rather than waiting for a break between acts. Sometimes the same ad plays 2 or 3 times in a single ad break, which does not serve the audience or the advertiser.
It would be much better to show ads at the beginning and end of each program, as used to be the case on SBS.
Ads and promos mid-program destroy the continuity and make the otherwise excellent programs unwatchable. I sometimes record and watch offline, but still the constant fast forwarding over ads destroys the enjoyment.
Yes, if SBS must have ads, go back to ads only between programs.
ABC had no ads so why not SBS as well
The adds are as bad as the commercial stations,so consequently we never watch a film and usually view our favorite programs On Demand where normally there are less adds —- Annoying to say the least.
Not only are there far too many ads and promos on SBS, but they also have the very annoying habit of introducing the next program while the credits of the previous one are still scrolling. I don’t know about anyone else, but I find this intensely annoying, and it should be stopped. A program should be able to finish properly without this sort of blatant, arrogant and disrespectful (to both the viewer and the people who produced the program.
SBS has some great documentaries and other programmes, which were watchable when ads and promos were shown only between programmes.
Now the programmes seem to be structured around the ad breaks rather than vice versa. (A prime example is Mastermind which is broken by ads & promos twice, while there is a direct transition – i.e no ad break – straight into the following news bulletin)
If ads are necessary due to lack of govt funding, please consider WHEN they are shown as well as how many. Disruption of programme content is not necessary.
Promos are excessive,repetitive and annoying (ABC too)also often violent or otherwise inappropriate for family viewing at prime time.
I agree wholeheartedly with others about the content and repetition of promos and ads.
no comment
SBS currently my favorite channel … The ever increasing number of ads is changing my stance
I have only just started using a tv to watch SBS programmes, previously I was using SBS On Demand on a laptop and had been able to block ads. The amount of disruption to programmes is unbelievable! It prolongs the time I have to spend in front of the tv if it is a programme I really want to see on a decent sized screen, and means I am constantly hitting the mute button and having to check when the programme is back on as I am not interested in actually looking at the ads….is anyone? especially as they are so repetitive! I agree that fewer ad breaks during programmes is essential and they should be placed at beginning or end of programmes, often the next programme starts right after the last allowing no time to do other things if you want to watch both. Also gambling and junk food ads are extremely inappropriate on a government supported broadcaster.
Ads on SBS will lead to the self destruction of the service arising from dedicated viewers going elsewhere. DON’T LET IT HAPPEN
We deeply resent the ads placed in the corner of our screens while the program is in progress Let’s stop this practice as it affects concentration and enjoyment.
Too many ads and too many gambling ads!
It’s the old adage of “give ‘me an inch, and they will take a mile”.
SBS started off with “just a few” ads.
Now look where we’ve ended up!
The SBS has changed and not for the better. It has become a commercial channel with a different slant. The ads are just
too many and annoyingly repetitive. The gambling ads are very , very disappointing- they should have no place on SBS, and preferably removed from all TV channels. Senior management should be removed and new talent brought in.
ABC is better to watch because they don’t have ad breaks in programs.
I would watch SBS more often (especially OnDemand) if there were no commercial ads; I absolutely hate the gambling ads. I use the MUTE button often!
I dislike any gambling ads and they are muted if I’m watching TV or FF if watching a recording. It is disappointing that we don’t have a proper Public funded broadcaster any more. I enjoy watching the French News in the morning – no ads.
The all too frequent interuption of programming is very frustrating. This includes with streaming. As the program progresses the ad breaks get more frequent often disrupting the flow of the story. This destroys the joy of the entertainment. Ads also make it a much longer experience particularly with movies. Such a shame this wonderful service had been wrecked in this pro commercial, brain washing way. The constant replaying of the same ad often drives me crazy too!
Look I understand that the extreme Feds have inflicted financial pressure on the SBS network, but the line in the sand must be re-drawn and adhered to …. advertising of both types is destroying an Australian cultural icon.
Less frequent but longer ad breaks would be preferable to the current program disruptions. A break every 30 minutes would be fine.
I struggle to understand why it is necessary to have ads repeated within the same ad break.
Ideally ads should not be needed by SBS but given government failure to do this then some are acceptable at beginning or end of programs. No gambling, alcohol or junk food ads should be shown at any time.
Constant reputation of some adds add to the frustration. Whether this is a marketing strategy it is deeply annoying. SBS promos time seems overdone also. Thank heaven for my mute button
I espeically hate the ads in SBS Catchup
I record any SBS programme I want to watch – and it does have some really excellent programmes – because I have zero tolerance for all ads, especially the gambling ones.
it’s not good enough
There are typically 3 x 3.5 minutes breaks in a 1 hour prime time slot making a total of 10.5 minutes of advertising promotion per hour!
I support a modest amount of advertising to enable SBS to continue.
But if SBS viewers are Blitzed with advertising interruptions similar to the commercial channels then everyone is simply going to switch off or use a digital recorder to fast forward through the adverts.
Why can’t SBS have commercial breaks at the beginning and end of programmes,as other countries do ? And gambling ads MUST go.
We are so sick of the ads on SBS. They seem to go on forever. We record programmes now so we can ff through the ads. When we lived in Germany years ago, we saw the programme and AFTER that all the ads on after the othe≥ At least we knew we could get up and do something else for 20 minutes, or mute it and talk.
SBS is becoming frustrating and unwatchable.
I watched the streaming of one episode of The Salisbury Poisonings last night, and it was excruciating the number of ads involved. I’ll have to grit my teeth to watch the rest!
It seems that many other folk also record SBS news and assorted programs, so that they can skid past adverts on our Public TV Broadcaster(?) Ads are therefore never seen.
Otherwise a good book is worthwhile.
I rarely watch SBS anymore because of the ads. I wouldn’t be surprised if the purpose of forcing SBS to screen ads is to turn away viewers.
too many repetitive adds. The same add is repeated every day on one of the programs we watch, plus the same promos over and over again.
We want no gambling adds
Repetitive ads and excessive promos are driving us away from SBS. Such a pity as SBS has great programmes. Ads only at the beginning and end of programmes PLEASE.
I agree with previous comments. The ads are now unethical and promote damaging things such as gambling. It’s crossed a line. The ads in both frequency and timing are unbearable – even when you stream stuff. Surely this runs counter to the SBS charter? It’s sad the damage that has been done to a brilliant multicultural resource by a bunch of white people ðŸ˜
I also only watch free to air SBS by recording shows I want to see and skipping the ads. I refuse to watch On Demand as you cant skip the ads. I would be prepared to pay a subscription for On Demand with no ads.
Further to my previous post another very annoying thing is the promotions over the top of the end credits of a program. Very annoying and disrespectful.
The number of ads and the frequency of the interruptions to chosen viewing, act as a great disincentive to watching SBS programmes. Yet SBS offers quality. with a very broad range of appeal, and is markedly different to commercial television in particular. What a waste of potential. It would be wonderful to have advertising removed altogether from SBS.
Too many ads and too often. I begin to think “what was I watching” and turn over to another channel or turn off.
I’d watch SBS all the time if it weren’t for the disruptive ads. Why should public services have to be supported by private enterprise? It’s just further evidence of the failure of neo liberalism and personally – I’m over it. Please try harder SBS.
I hate the advertising on SBS and so now only record programmes that I want to watch, so I can forward through the ads.
While I used to watch SBS live for programs within my viewing hours, such as the news and early evening programs, I now find it much more pleasant to series record most of them and fast-forward through most of the ads (although sometimes watch those about forthcoming shows on SBS). Viceland seems particularly riddled with adds, breaking programs at unnatural times.
SBS, like the ABC needs decent funding. They both offer excellent content, but SBS has degraded their content with horrible repetitive advertising. Who voted in that mob in Canberra who give handouts to Murdoch while emaciating our ABC and SBS? The ABC and SBS offer the civilising and educative influence Australia needs or we will become a more self-centred, non-community focussed rabble like we are seeing in USA.
Gambling adds should not be allowed on any TV screens whether commercial or sbs tv – gambling is a very costly social health problem that does not need pushing to those most vulnerable.
We used to love you SBS, but now we just can’t watch you anymore. (We do not watch commercial stations either for that reason)
Much as I enjoy SBS, there are as many, if not more, ads than on commercial stations. Gambling especially has no place on SBS. Having ads is inevitable it seems, much as I long for commercial-free television. Let’s keep it within reasonable limits!
Give us back our SBS
I rarely watch SBS live any more, the interruptions are intolerable. However, I do love most of the content so record the programmes that appeal, sometimes editing out everything that is not part of the programme or film, if I want to save it for later viewing. I agree that SBS on demand is spoilt by the compulsory viewing of breaks for ads etc.
If we have to have ads, and I don’t agree they are essential on our precious public broadcasters, the fact that they are programmed to interrupt programs indiscriminately, is an abomination. If there are actually more than necessary, please remove them post haste. What is the purpose of this organisation? To advertise? I thought it was to run programs that inform, educate and entertain, particularly about and for our diverse multicultural society. The ads are just a necessary evil to assist the balance sheet.
SBS was intended to be a service for the migrant community of Australia not just another media organisation. It’s time for that to be put front and centre of its operations. A central mpart of that is the removal of ads from the program mix.
The ads in SBS World Movies seem to go on for ever.
I tend to watch SBS and the ABC for getting TV news – although I get a lot of news and analyses from the alternative progressive media.
Commercial TV news bulletins are generally an insult to on’e intelligence. I find that often that SBS TV news is better than ABC TV news, however, the number of ads on SBS greatly distract from its news bulletins.
U think public media should be free from ads.
I “mentally switch off” during these frequent, disruptive advertisements which I think are ruining the reputation of our unique broadcasting service. Please get rid of these advertisements which are destroying the integrity of SBS which is an Australian Living Treasure.
I find particuarly annoying interruptions that are placed at crucial moments, especially during a film, when such interruptions prevent me committing myself to the storyline and having a refreshing experience.
Films that once flowed from beginning to end are now frustratingly interrupted a number of times with repeating ads., seemingly self-defeating commercially, and a complete break in the aesthetics of the film. SBS once acquired a positive worldwide reputation with the enterprise of its film choices and the quality and availability of its subtitling. Now, SBS on Demand shows quality films, but the ads. are no encouragement to watch them.
The adds drive us crazy. The fact they they are soooo repetitive during a programme men’s it even worse.
Agree with above comment re not being able to scan thru to a paused place can’t be achieved without the adds being repeated.
Takes the joy out of watching SBS.
Now we watch more on Netflix
Please get rid of those Robbie Williams ads promoting a radio station.
SBS: please stop advertising during programs. It reduces the time we spend on SBS each week to about 2 hours, from the perhaps 6 or 8 hours we would watch if ad-free programs. We NEVER watch commercial channels because of the ads.
So frustrating to have ads interrupting quality programs as they intended to be watched, especially feature films! It seems to be getting worse by the month. SBS viewing is more and more like watching a commercial channel. Actually, it now is a commercial channel…
Advertising and programming is getting so bad I am watching less and less SBS and have taken up more reading of novels.
With such a great choice of programmes from around the world we are being subjected to mindless rubbish for the sake of revenue. It’s just like all the other commercial channels, which I no longer watch, and will eventually self destruct as nobody will watch it. A scandal.
Yes SBS give us all a break. Its like watching the worst of the commercial channels and that’s saying something. Is there a reasonable bone left in any body of media? I dont think so.
Too many ads spoil the moment,,, esp when we’re watching a good movie. Too many ads are annoying. The only ads that should be on are the ones that relate to Animal Welfare,,, eg Animals Australia or other Great Organisations informing the public where their food, clothing come from etc. this stuff, we should be told about.
SBS is a vital Australian media service and vital cultural entity.
It deserves our most considerate nurturing through full public funding, and removal of commercial advertising.
Regards gordon
Apart from some news items, I no longer watch SBS. If there is a program, I will record and then fast forward through the adds.
Basically, SBS has become a commercial station, and for me, has lost its relevance as a public broadcaster. How beholden are they to their advertisers?
I think the time has come for any SBS public funding to be given to the ABC and for SBS to compete with the other commercial stations.
I love SBS But believe it is often spoilt by too many adds breaking up good programs and in the wrong places.
There is frequent repetition of the same promos-I don’t need to see them hundreds of times!
Please, don’t make our entire lives a commercial opportunity. Allow us to flourish as humans without the corporate sponsorship!
I’m glad of this research and petition. Sbs has marvellous content but why on earth is it being polluted with so many ads and repetitive promos of their programs? It’s really ruining the pleasure.
Give us back our SBS
Keep SBS special and free from ads!
SBS stands for SHOULD BE 100% SUBSIDISED by the Australian Federal Government!
There is ABSOLUTELY NO NEED FOR ANY ADVERTISEMENTS ON SBS!
SO MANY GREAT PROGRAMS should be seen without crappy advertisements and dodgy promotions to interrupt them and make them UNWATCHABLE!
Millions more people would enjoy SBS if there were NO advertisements!
P.S. Al foreign language programs should have English subtitles. That way, many more people could enjoy the overseas/foreign-language News Bulletins and other foreign-language programs.
We rely on SBS for World News…who else other than the ABC can we rely on? Id rather watch SBS that have to try to work out what is true or false from the internet or the other TV stations.
The whole foundation stone of the SBS is being destroyed.
Her role as a multi-cultural educator and assimilation media platform has no equal.
The SBS has a very dedicated diversified audience including me and does NOT take kindly to this
arrogance. Beware the advertisers who will definitely expect a backlash.
The ads on SBS are so annoying that I will find another source for an interesting show that I want to watch. I dislike ads so much that I would rather read a book than watch them on TV. On my computer I use Linux, Brave browser and numerous ad blocking technologies to avoid ads. Ads are the bane of our modern existence.
They have too many upcoming programme advertisements as well.
When I started working at SBS in the mid 90s a half hour program was usually delivered as 27-29 minutes (allowing 1-3 minutes for between-program announcements and, occasionally, a little creative “interstitial” masterpiece). Ads totally changed all of that, and programs bought-in are summarily butchered to ever-shorter lengths.
Whatever has happened?
For a channel that continually boasts that it is ‘different’, the sheer number oif increasingly moronic adverts make SBS look just like – or worse than (if that’s possible – than commercial sations
I completely agree with previous comments about gambling. I deeply resent the amount of gambling ads in televised AFL matches; now SBS are doing it. I know gambling brings a lot of revenue to the government but it also brings a lot of suffering to families and causes a great deal of disruption, including family breakup, which is also costly to the government (Sole Parenting payment, extra children’s payments, administrative work involved in Child Support etc.). We are much better off without them.
Nothing to say
The other night I was so angry at a run of ads that seemed to go on forever that I did a count at next break – results was 12 ads, plus promos as well.
By the time the program I’d been watching came back on I’d forgotten the story, lost interest and gave up on the whole thing. Switched back to ABC-TV.
If SBS thinks that “angry” is worth paying money for, then they’re idiots.
Instead of advertisers “selling” me their stuff via SBS, it’s just a big turn-off.
Since ads appeared on SBS ad free spaces have become even rarer. SBS should be the way it was intended.
Please fund our SBS to a more reasonable level to avoid over reliance on ads. I agree with above that ads for things such as gambling are offensive and not matching the station charter or culture. Political will to close ABC and SBS channels must be stared down. Commercial channels are so poor in reporting news and also awful drama in the cheap and nasty reality shows. The quality of SBS in providing world news and excellent adult drama must be continued but without the ads.
We desperately want our original SBS back! Please stop all the ads. We switch to other channels to avoid them. They are too numerous and too long.
I have stopped watching SBS On Demand, because I find there are too many adverts. The ads were too annoying to bother watching SBS On Demand.
Please reduce advertising to restore the viewing pleasure toSBS
I cop enough advertising in my day to day life without it being shoved in my face in the ONE place that has always proudly been marketing free. ESP from gambling and crappy food advertising!
The quality of SBS’ output has plummeted over several years, and the quality of their presenters has also diminished. I also do not understand what benefit accrues to SBS when they show a complete series on SBS On Demand before it is aired. And their On Demand facitlity is woeful – difficult and very slow to navigate.
The placement of ads is very obtrusive and spoils much of the enjoyment from watching a programme. They seem to be deliberately inserted at the most inopportune moments. And you can’t easily avoid them when streaming! I’m definitely not a fan of Viceland, but overall I think SBS and World Movies are probably my favourite channels for programme content. It is a crying shame that commercials can’t be confined to the breaks between programmes if we have to have them. Advertising as we know it is no longer effective. Everyone I know records programmes so they can fast forward through them. And I don’t know anyone who actually watches/enjoys/takes note of what they are selling. Please practice restraint with your advertising strategy or run the risk of losing more of your audience to streaming services.
commercialised TV sucks!
What happened to our preferred, quality broadcaster? Frequent intrusive and disruptive ads have made it unwatchable. And for a public broadcaster, gambling ads are unethical.
Compared to commercial channels SBS isn’t as bad. The repetition of the same adds over and over is annoying.
The ads are a great deterrent to watching SBS at all. There are too many of them. They are poorly timed – not placed in a natural break in the program. At times an ad will be repeated twice in the same ad break – exceedingly annoying.
Have SBS air dinkum Aussie promos … more Football, as in Australian Rules, Rugby League and Rugby Union, (even Gaelic footy), and less Soccer which is the easiest game to learn and to play. (The lowest common denominator?)
Adverts on SBS are a nightmare. Seen too often, disruptive to viewing, and annoying in content.
I am aware that SBS depends on ads for funding but it is done so badly, that whoever is responsible needs to GO!
This channel used to provide an excellent service but now has sold its integrity to commercials.
SBS was so special, and was viable. It is deteriorating, with all the commercials. Some are so insulting to the viewer, with the same sets being repeated, sometimes even more than once, during a program – and even during the same ad break!. All one can do is get on with the washing up, or other chores But that is not what the character of SBS is supposed to be.
As a viewer, I find I have to ‘manage’ the constant, repetitive commercials, by getting on with other tasks OR recording the program to view it later, scrolling rapidly through the commercials. The former way gives a broken viewing session, and works better for programs that are mainly voices.
I don’t really care about the Quality of the ads, i.e. whether they are pretty or witty. Rather, I just think they should not be there in such profusion. SBS was a unique, and publicly owned channel, and now is quite a bit like the commercial channels. A good channel like SBS (was) would gather momentum from beyond Australian shores Please remove the advertisements, and return SBS to the character it was conceived of having.
It is another creative, inventive Australian icon, given a wash of mediocre beige, which in part disguises the actual programming, and raises the possibility of reduction of independence of thought and ideas within the programming.
Not to mention, I’ve noticed a lot of ad breaks and promos have very different volumes from the tv shows.
I have some serious anxiety issues and sensitive hearing, and these LOUD adverts scare the heck out of me. I often don’t gain my regular breathing pattern back until the show starts again.
I don’t think SBS intends to scare me with sudden LOUD NOISES,but they do. And it really puts me off watching SBS (doubly so when there’s too many adverts and promos, especially repetitive ones).
It’s so annoying as hell that S.B.S. is forced to jam commercials into their fine programming.
It used to be wonderful that at least we could enjoy a program without ads on SBS , what a pity we were forced to have ADs on this wonderful channel just to have our SBS, now more than ever , it seems that SBS is showing too many ads, especially when one is trying to watch a good movie. It seems to me that this has gone beyond normal, and we might have as well watched the other channels as every five seconds we are forced to watch yet another stupid advertisement, when will it all end? I want my old SBS back please!
The repetitions are particularly annoying.
Far too many promos. I get so sick of seeing the same ones over and over again for weeks before the show is due to start. I record most SBS shows so that I can fast forward the ads! SBS used to be great – now it is just another commercial station bombarding viewers with ads.
I access SBS programming from SBS-On Demand these days – it’s more convenient with fewer ads and shorter ad breaks.
They are forced into taking on advertising because the USELESS government under-funds both SBS and ABC!!!!!!!!!!!!!!
I would like to see fewer ads on SBS and absolutely NO GAMBLING ads!
please return to a pre-ad SBS! surely it can be done sensitively without destroying the SBS budget.
I find the excessive advertising and promotional inserts to be irritating and disruptive of my viewing pleasure.
In particular, I am galled by the incessant recapitultion that documentary makers are compelled to include in order to re-establish the flow of the narrative.
The importance of SBS has been underestimated by our federal government. SBS shouldn’t have to seek advertising revenue. This is fundamentally wrong. SBS is important to the diversity, entertainment and education of all Australians. Adequate government funding urgently required for the health of the nation.
All betting adds are repulsive. They have the potential to harm all levels of society especially children. Remove these adds straight away
We need the original SBS format. An increase in Government funding is imperative for continued independent journalism.
SBS programming is the best but I’m hardly watching anymore. Why? Ever more interruption of programs by ads of course. It’s ruined the SBS experience.
Diversity in the News landscape is essential for a good functional democracy.
I wish that the political landscape will change and a good critical journalism get the resources for increase his capability.
Nice greetings from an Australian in now Germany :)
Far too many ads and gambling ads should be wiped from the screen altogether.
tiring. ….and then you want to stop watching altogether.
Yes, there are WAY too many advertisments now on SBS.
I also find the PBS News hour broadcast REALLY does my head in as SBS uses their American ad-breaks to place even MORE commercials. Why?
Please give me back the original format of SBS without the noise & stress of advertising distraction during broadcasts!
The ads have driven me away from SBS.
I want to watch the excellent content but the viewing experience is punishing because of the advertising.
More and worse ads, fewer viewers, higher percentage of irritated loyal viewers almost ready to give up and move on… not a great social or business model.
Tax payer funded, private advertising and cuts to staffing add up to the same as a commercial venture. It is a great service and being ruined by marketing and a push to make money – for whom?
Bullying of good staff and crew is included in this package. Good on Straya for not being able to look after its world class media and people who work for it.
I am also really pissed off still that HD TV took SBS Vice and deleted my good free-to-air television technology to watch SBS Movies. WHY encourage more E-Waste with my tv being redundant to pick up the HD stations? FFS!
Very much disappointed with the news coverage by SBS during the COVID-19 scamdemic. It is not much better than the ABC or rest of the mainstream media in reporting with an investigative, unbiased, propaganda free demeanour.
Consequently, about the only source of more accurate factual information and alternative perspectives can be obtained by an aggregate assessment from online sources.
Not for posting as a comment- can the site organisers please highlight the anti spam requirement before the “post comment” button, or provide a second chance to answer if submitting comment without completing the requirement? Didn’t see it on mobile view before submitting my first comment. Makes it easier for us to support the great work you’re doing. Thanks!
I agree with the reasoning that IF SBS must have ads then they are run in a block at the start, and midway (as an interval). The peppering of Ads and Promos is destroying the viewing pleasure that SBS offers: leading to this viewer watching less and less. May I suggest that a similar check of Ads and Promos be run through the On-Demand serials, and to a lesser degree Movies, as there are times when they become unwatchable and seem to be run very close together. Again if Ads are necessary then run them in blocks at the start and middle.
The ads are annoyingly interuptive, make no sense where in the programme they appear
I am sick of dumb ads and I am particularly opposed to gambling ads.
Annoyed by the streaming ads that go for a longer time during increasing breaks within a program. Please bring back the old SBS.
The gambling ads are especially distasteful and ethically questionable, given the the damage that gambling can cause. By depicting gambling as innocent fun, the ads constantly chip away at SBS’ integrity. Does the board seriously support this promotion?
We used to favour watching SBS, but now we hardly watch due to the excessive add breaks. I particularly do not like the gambling advertising, I find it offensive. Would love to see return of original SBS.
No gambling ads!
I find it really disappointing that watching SBS is like watching commercial TV now. Its good content but brain torture to have it interrupted. There should be NO ads on SBS but for heavens sake how did it get to where it is now that every few minutes we are interrupted. Its a form of harassment.
The advertisements are distracting and CC at times inappropriate. NEVER should there be gambling advertisements they are against the well-being of the community. I would also appreciate less repetitive food programmes. It’s clear the SBS needs to review it’s programming or at make them current.
It is such a shame to see SBS ruined by too much advertising. The station is almost unwatchable now. I look back on the early days of uninterrupted viewing with longing. What a pity! I particularly dislike the repetition of the same ad in one break. Stop destroying SBS!
If there has to be adds then I believe there should be some ethical and social standards involved. Environmental and social issues should be considered, no gambling, no fossil fuel adds, nothing that would marginalise social groups or put disadvantaged groups at risk, alcohol, gambling etc. All we should be buying are necessities, luxuries marginalise and lead to disharmony.
SBS had an advertisement of clean coal a number of times. I stopped watching the feed if i want anti science or anti sense I go talk to my neighbours or join a trade union they are fine with that, its the terrible values that are being advertised as well as the frequency of the miss information. So its not only the fact SBS has these advertisements, its also what sbs is selling for me as well I find it deeply disturbing and unethical as well. I stopped listening not just because of this but in generally much because of the frequency of this type.
We switch from SBS often due to the number of adds & repeat ones too. Gambling promotions must be banned for the good of society. So sick of them all. STOP privatization and bring back public funded services for the people. Tired of greedy corporations without ethics.
Worst of all is the way ads often freeze SBS On Demand with growing frequency so that it eventually becomes impossible to watch a program past an ad break. We are seriously considering giving up on SBS, our previously favourite broadcaster and streamer.
Advertisements have the ability to discredit the integrity and honesty of SBS.
We need to fully trust the SBS and all its messaging.
No advertisements for SBS.
The SBS is a national treasure and shouldn’t be undermined by politicians like the NBN.
Too many adds and for goodness sake Gambling adds should be banned altogether
SBS is one of the best channels in the world (without ads).
If SBS want to make money- do a deal with TV New Zealand. We are so close in culture and people that you would find many avid viewers in NZ. They follow the BBC but how much more attractve would it be to follow Special Broadcasting Service from Australia.
The increase in the number of ads on SBS
Is unacceptable and annoying. As a publicly funded channel there is no need for the current volume of breaks in programming.
Also, the type of ads are disappointing.
SBS is a national treasure and should be properly funded with minimal ad breaks. Any of its news content used by Google and Facebook should also be subject to the same new legislation as commercial channels so they don’t have to rely on disruptive ads.
Too many and inappropriate adds.
I do not listen or watch any programs with ads. Could you imagine listening to music and an ad interrupts it! I feel the same when I am watching a TV program. No ads please. If there was a paid prescription service for ad free SBS on demand, I would pay for it.
SBS has become advertising heavy which denies the multicultural and community focus of its establishment.
Ads are mind-numbingly torturous – please return to NO ADS!!!
Unfortunately SBS is as bad or worse than commercial stations as far as ad breaks & promotions are concerned. We used to love SBS but because of these annoying breaks & so many gambling ads, we are watching it far less now. A shame because SBS was a great station which always had interesting & informative programmes.
SBS is lookijg more and more crass and commercial. Loud, disruptive ads are clumsily thrown in to programs in the most inappopriate places and disrupt viewing in a very annoying manner.
Even on On Demand, when replaying a program, all of the ads have to be seen again.
Gambling asverstising is immoral, amd should never be shown on SBS.
SBS, which used to be a high quality viewing platform, has been dumbed down to a commercial enterprise.
What the government and the advertisers do not understand is that on principle I would not buy any advertised product which interrupts my viewing on SBS…that we cannot have an ad-free pubic broadcaster such as SBS is a shameful reflection of the low esteem the powers that decide have of the service.
Such a pity to see this overuse of ads that spoil the fine programs SBS offers. It puts SBS into the ranks of commercial broadcasters rather than the quality public realm it once was part of.
As a person with an continuously worsening hearing loss that has no current solution, I now record ALL SBS programs and read the sub-titles. If the sub-titles flick on and off quickly or are difficult to read, I can rewind and pause to read the sub-titles. Ad breaks are either fast forwarded through or used for comfort breaks.
The ads do not fit in with the profile of SBS – they are purely commercial.
We realise SBS has to have some advertising to keep going, as our government doesn’t seem to understand the importance of maintaining this really Creative multicultural television channel, but what is happening now from lack of support is extremely sad and frustrating.
These days I select a programme I think will be good to watch and record it, so I can fast forward through the mainly awful advertising.
SBS used to have, some of the best most creative advertising that was great to watch more than several times, The need to stay alive has squashed this.
I love the SBS channel, and will always support you.
Best wishes for a better future on air.
I rarely watch SBS because of the adverts
I’ve actually had to stop watching SBS because all the interruptions and the awful ads, which are just repeated twice in a row, make the viewing a chore rather than a pleasure!
I enjoy promos so I know what new shows are coming – these can easily be shown between programs not during them. I get the need to advertise – SBS needs the income, but they are way too repetitive, and at times are chopped into the program at really odd times.
SBS Is just another taxpayer funded mainstream media outlet that is biased, SBS news repeates the biaed main stream narrative with Taxpayer funding, an absolute disgrace.
Although it’s understandable that SBS needs money, many of the ads are intrusive and unwanted- eg. funeral insurance, weird kitchen utensils and bedding – cheap, shouty ads. This often brings down the contents and atmosphere of shows and disrupts flow, frustrates viewing.
I agree that there are many more promo breaks on SBS than on the ABC.
I dislike commercial breaks altogether.
Frustrating all the adverts. And with SBS On Demand there is no escaping the ads. Both SBS & ABC public broadcasters should be independent and properly funded.
We used to watch SBS & ABC divided equally but now it has shifted to mainly ABC.
I agree with Helen Best
The most destructive adds are gambling and fast food adds.
Gambling adds are hugely damaging, especially to children.
Advertising gambling and fast food – the cause of so many health and social problems – is just so, so bad. While we have the mute button at the ready, you can’t relax. These ads and the sheer number of ads ruins watching the high quality programs on sbs.
Very disappointed
I can’t stand the ad breaks on SBS. I love the programming but it really puts me off turning on that channel now.
I used to love SBS years ago but stopped watching when advertising interrupting programs started.
I would like to see my taxes go to a decent public broadcaster with extremely limited ads prefer none as I also have turned to Netflix where there is no ads. As it’s my taxes that help to pay for the ABC and SBS after a hard day’s work I don’t want to be inundated with advertising especially gambling which destroys so many families and lives let’s get back to what these things were originally created for, to be informative, educational and good entertainment particularly at a time when we need some inspiring stories.
So the Federal government is intent on destroying what in my experience was the best TV channel in the universe.Why?I already only watch the ABC while faintly hopeful that SBS will one day resume its mantle as the most interesting & inclusive TV channel worldwide.
The ads are too long and there are too many promos even though they are allowed.
So frequent and sooooo repetitive.
I understand that the funding imperative for SBS make advertising necessary, but there are ways to handle this without disrupting the programs. One is to put all the ads up front. Secondly, I would be prepared to pay a subscription fee to avoid ads all together. SBS’s program chooses are way better than any other streaming service and I would be happy to pay for this. Currently the ads are putting me off watching SBS.
repetition & constant interruption is nauseating
Importantly I take opportunity during the ads to Have a break myself and get up and do a few things.
Ads are well spaced and better quality in general than those on commercial TV if I do have to watch.
SBS was my default station. I used to watch sbs all the time but lately have had to cut right back because so many adds and promos interrupting what are still great programs..it’s a waste of the hard work and cost that goes into producing a program if it’s constantly disrupted by irrelevant material. It also makes me antagonistic to the product being advertised !!
I find the repetition of ads for SBS programs a great annoyance. I see no reason for running the same advertisement twice let alone more often in a hour. I recognize SBS needs advertising revenue but they should communicate to commercial advertisers that repetition of the same advertisement in a short period of time is counterproductive – at least for this viewer.
I would not watch SBS if I had to watch it live. The ads are disruptive. I record the programs I want to watch and view them when I choose. However it is still annoying to have to fast forward through the ads.
The amount of mind numbing ads, both commercial and in house, is a huge disincentive to watch SBS.
The ads wreck the flow of the program. We’re forced to record shows that we really like and then fast forward through the ads when we re-play.
I only watch SBS when recorded so that I can fast forward the adds, they are so many and so distracting. What is happening to SBS is a foretaste of what the Liberals want for ABC
Way too many adds about food during an obesity epidemic
Amongst other things
Repetitive adds disrupting viewing
Netflicks movies are much easier frankly
There is no reason for SBS to carry advertising at all. Advertising is annoying and irrelivent. Sometimes i turn the tv off rather than try to watch a show that has been cut to pieces.
My MUTE button is experiencing excessive wear and tear.
Agree that too many ad breaks diminish the quality of SSS which is a national treasure. Originally when quality of the early adds were few and of worthwhile businesses but advertising gambling is the pits. It ruins the quality,informative programs
It’s time a really strong “Save SBS “ was pushed
I have given up watching SBS on Demand. Far too many ads. Whenever I log on an ad pops up. I’m not sure why, but often the screen freezes and I have to reload the page, generating yet another ad. Apart from that many of the ads are repeated ad nauseam. There are many good shows but far too frustrating to watch.
SBS has always been my highlight of television viewing. Unfortunately over time the ads have escalated to a degree that tm starting to shy away from my favourite station. Please bring back the original format of SBS & leave the interruptions & commercial programming the the other stations. Thankyou and good luck.
The advertising is pervasive and annoying and this was all introduced to cater for the whinging from commercial channels who cant attract an audience.
Please get rid of ads altogether and go back to how it was designed in the first place.
Many times I have counted 5 ads one after the other. Seems like it’s just a money making junket!
You have destroyed SBS with money making advertisements. Gambling adverts are offensive and a turn off. There are far too many interruptions destroying the purpose of the station.
There are other ways to fund the SBS.
For example the BBC is funded by TV licences and consequently does suffer the vagaries and uncertainties associated with political ideology like in Australia.
There are too many repetitions of the same ad in short roation and too many promos.
Whilst it is understood that SBS is required to broadcast some ads in order to keep going, GAMBLING ADS are “the bitter end”. For a broadcaster who has demonstrated that they have a social conscious through the kinds of programs they broadcast, gambling ads are at odds with this. Gambling causes misery for hundreds of thousands of families in this country – NO MORE GAMBLING ADS.
It’s obvious!
Deliberate ruin of sbs/abc to the point where it’s unwatchable/ratings go down, channels get defunded.
Governments world over are on the same channel,stifling woke thinking, control the masses,feed them new gov positive lies & propaganda.
Aint seen nothing yet folks.
We are being blindly being stripped of all the freedoms we once enjoyed. Disinformation & misinformation are governments weapon of choice.
SBS and ABC used to provide an amazing service to Australian citizens both here and abroad and I am baffled as to why the powers that be are trying to destroy both of them by reducing funding. It is a disgrace. They finance all kinds of ridiculous causes yet here is something which educates and entertains so many people and step by step, inch by inch the sabotage continues.
What a sad state of affairs – SBS has been lured into excessive advertising including ads for gambling. Too many ads disrupting what are generally excellent programs.
Sadly ii find it iimpossible now to enjoy SBS’ quality programs because of the excessive number of mostly repetitive ads and promos. It is no longer a public broadcaster, just another crudely commercial channel. Even pre-recording and fast-forwarding ads is no longer an option because of their frequency. Ironically the lure to advertisers of captive viewers has totally backfired as more and more viewers like me have stopped watching SBS.
Gambling and junk food, two problems that cost society a heap of money should not be allowed on any television station ever let alone one that was intended to be publicly funded!
Often while watching various Series on SBS on Demand it is totally frustrating when not only are there too many breaks for ads but often after an ad, the Series programme does not return and you are faced with a blank screen. It is then necessary to back track and find the programme to return to the Series and place you were watching in the series. This can happen several times in one Episode. I want to support SBS but this is very frustrating. Government funding would solve the problem.
Unfortunately is does influence my decision to watch some SBS programming knowing Im going to have to tolerate what does seem excessive advertising during some periods.
While not liking it, I can accept that SBS requires some advertising as they are underfunded by government. What I cannot accept, however is the serious overuse of promos and service announcements. I assume they are there as programmes designed for commercial channels are made allowing plenty of time for ad breaks and still fit half and one hour timeslots and are used to fill in time. I suspect most SBS viewers are capable of planning their viewing to work around this, perhaps they might even stay longer on your channel. At least SBS is not as bad as some commercial channels, I have timed, after 10pm ads, promos, and news “Updates” (Taped prior to 6pm)of more than 30 minutes per hour on some of them with 90 20minute movies taking in excess of 3 hours to screen.
Get rid of the LIBS and bring back our former SBS
SBS and ABC are my first choice to go to but the amount of ads on SBS, are very annoying, especially gambling ads.
There are indeed far too many ad breaks and they are far too repetitive- we often see the same ad repeated every ad break on Sbs on Demand ! And worse still, those ad breaks often cause a failure in transmission and we have to reboot the entire program, sometimes a number of times, which is very annoying, disruptive and time wasting! I also agree that there should be no gambling ads at all! There is no such thing as ‘ responsible gambling’!
Creeping death. It’s become worse and worse.
We live in a fake democracy where communuty views are ignored by a leadership who think they know best or have self interest motives which is corruption
Advertising should be stopped and in particular unethical advertising such as gambling.
I gave up watching commercial channels years ago because of the ads, silly, repetitive and so utterly spoiling towards the end of a good movie… it’s getting to the point I’ll be doing the same with SBS.
As it is I’m watching more dvd’s than ever.
Viewers of a cynical nature might wonder if the proliferation of ads on SBS is designed to drive us away in exasperation. Then, with falling viewer numbers, there’s a perfect excuse to get rid of SBS altogether.
Stop all gambling ads
I have given up on the superior programs on SBS because of the frequency and duration of advertising
There should only be ads between programs around 5 minutes and no gambling advertisements. Government funded tv should not promote gambling.
Having worked through much of my carer in advertising, I find it next to impossible to understand why it makes such great efforts to annoy its own viewers.
Too many ads – kills the program.
The ads are counter productive… as well as being low grade commercial productions. I wouldn’t buy anything that has caused me so much dis-pleasure and angst! Just get rid of them and return SBS to the quality broadcaster it once was and was envisioned to be.
Underfunding by the government surely is the issue here. The ABC offers little but current affairs and reruns. As usual, we can lay these problems squarely at the feet of this most objectionable federal government.
Ads are so bad now we record what programmes we can so we can skip through them! When you’re streaming and scanning through a programme to find a particular place you can’t skip the ads you’ve already seen!
Advertising on our public broadcasters is a travesty.
SBS viewing used to be a pleasure with advertisements placed considerately between programs. These ads were often of high quality and even entertaining.
Sadly over the years we have seen the increase in regularity in, almost violent, midprogram interruptions of ‘Bunning Warehouse’ style advertisements leaving one scrambling for the mute button.
These advertisement clusters have become noticeably and infuriatingly longer over the years, affecting the viewing experience to the point where I rarely watch sbs anymore (sadly).
Too many ads,I switch SBS OFF BECAUSE OF THE CONSTANT ADS
SBS has lost my support except for On Demand which allows me to completely avoid ads. The gambling ads are totally unethical….shame on you SBS!
From being a most-watched channel In our house, SBS has become more a commercially loaded advertiser and far less appealing. Gambling ads! On SBS! Badly placed ads, one after the other on SBS! Promos. What feels like constant interruptions to programs, all destroying stories of interest. SBS appeal fading.
I think having gambling ads on SBS is counterproductive to the investment the government (tax payers) pay to assist families in crises due to gambling problems. Why on earth is SBS actively promoting gambling?
The ads are also repetitive – again & again the same ad in the breaks. Makes you conscious of the product & determined NOT to buy.
SBS is running way too many ads. Particularly the GAMBLING ADS. I find them repugnant when poverty is rampant, and worry that children who overhear them are being influenced towards their own poverty.
SBS should not be a commercial ly dependant channel
The increased advertising on SBS over the years is unfortunate, with gambling ads particularly troubling. SBS is our public broadcaster, not a commercial enterprise, and should be adequately funded as such and with no ads.
I enjoy the SBS content and variety of programs. I have been sadly surprised by the amount of advertising Interrupting a program I am watching to advertise does not endear me to the product causing interruption. I understand the need for funds to support the channel, however the incessant interruptions are pushing me away from this channel.
Up to you SBS, keep the advertising and lose viewers or amend the situation.
SBS is becoming like other commercial channels with too many advertisements. The Government should fund SBS properly so they don’t need to rely on advertising to exist.
One has to desperate to watch a program on SBS due to the all-persuasive advertising breaks. Even with a PVR, SBS does something to it’s advertising content structure to make fast forwarding a challenge.
This point is entirely valid: We watch SBS 1 every night, but I cannot tell you the content of even a single ad or promo. Why? Because we record programs and watch them the next night, skipping all non-program material. Advertisers are wasting their money.
Ads on SBS break the continuity of viewing programs, especially films, and often result in us switching channels to avoid them.
Way too many ads, and what is worse, is having to watch not 1, but two runs of the same gambling ad within the same ad break. Disgusting! It s highly irresponsible to promote an industry that destroys the lives of so many.
I love the SBS content but it’s becoming more and more like commercial TV where the breaks seem to go on for too long. Let’s keep SBS the great station with intelligent content without the rubbish advertising.
I’ve given up on watching SBS. Far too many ads! Simply ruins any quality programming.
Any advertising is too much. But, no doubt, a necessity these days. What I find more aggravating is the quality of the commercials which are mostly crude and cheaply produced. And the products advertised, fast junk food and cheap and nasty stuff.
This may, of course, be simply my perception but SBS, like the ABC is known for quality television and I believe that the advertising should not be aimed at the lowest common denominator.
SBS has some wonderful programs and dramas which are sourced from all over the world.
The quality and range of SBS programs has improved so much, but the ads. are so annoying and as mentioned the gambling ads. are a particular Menace.
I frequently watch SBS for the quality programs but the incessant ads are a huge distraction. The government has a responsibility to fully fund SBS and woe betide them if they attempt to introduce ads on the ABC.
Adverts should like gold, rare and valued by sponsors not mind numbing repeats that are annoying and ignored.
A different market philosophy needs to be promulgated.
If our elected leaders recognised and respected the value of SBS content, and funded accordingly, then the need to go cap in hand to advertising revenue wouldn’t be necessary. I guess it takes some level of insight, and intellectual clarity to reach such a conclusion – apparently in short supply when funding decisions are made, and funding support eroded.
too many ads
None.
I would be happy to see the gambling ads removed.
SBS is well on its way to becoming a trashy copy of commercial stations.
It’s not just the ads that are concerning, it’s the political pro coalition news bias of late that is the major problem. Whoever is editing the pro coalition news service needs to be removed. It appears that coalition finance threats are working.
Firstly I would like to say I love the idea of SBS and viewers are fortunate to access overseas films and the wonderful range of documentaries. ALL of which are spoilt by the constant interruptions of adverts – such a shame. I guess the problem is lack of funding – maybe viewers like me who complain about the ads should be prepared to pay SBS for high quality production because if the government does not fund SBS WHO will – and current situation stands. What do other viewers think? I bet most wont want to pay a cent. Anne
I understand why they have increased and want to support the station because they have such excellent shows and they offer the best and, along with the ABC, most trusted news service.
Please, reduce the number and frequency of advertisements, it is too much !
Please restrict the adverts to natural breaks between programmes, rather than just randomly interrupting ongoing programmes – these interruptions are “amateur” in their nature, with no obvious discontinuity- sometimes it takes a while to realise that we’re watching an advert rather than part of the programme !
Too many ads
The volume of adds has steadily increased over the years making SBSdearly discernable from commercial television. The freqency of adds is possble the most annoying aspect, which disrupt the flow of a program, often at the most inappropriate times. If adds are necessary, having the in a block would be far more tolerable. I too record programs because of the adds, so they are wasted on me.
I understand that SBS needs the money from advertising to fund programming. It used to be that you only had ads at the beginning and end of programs … not during … and that was bearable. We have stopped watching much of SBS because of the adverts. The ad breaks are often very badly placed within the program and it takes the pleasure out of viewing the program.
The deconstructors are undermining all that builds commumity.
This is about wielding polital power. Not Parliament.
Of course this includes the erosion of the SBS.
It’s virtually impossible these days to distinguish between the commercial channels, the advertising on which is increasingly banal, stupid and insulting (don’t get me started on TV Shop ads!) and SBS. As far as viewer annoyance and irritation are concerned, SBS might just as well be another commercial channel. A deplorable state of affairs.
Not only do the commercials destroy watching SBS programs but they compound the excessive advertising and consumption which is destroying the earth’s biosphere. There are enough other venues for businesses to advertise than SBS.
With the dumbing down that has happened at the ABC, SBS is the only network in Australia delivering quality programming. However, it is increasingly becoming unwatchable, not only with the number of ads, but often with the massively increased volume at which the ads are transmitted and thereby increasing the irritation/dissatisfaction factor.
I used to watch SBS regularly but not anymore because of the ads. Trish T
If SBS continues to run ads like a commercial channel, it should be treated like a commercial channel and defunded. Why should the taxpayer be de facto subsidising the commercial entities which advertise on SBS?
Like all of the above, I am sick and tired of the constant bombardment of the ads and promos. It seems at times to exceed the amount of ad breaks on commercial tv. I will never buy any product pushed on this channel particularly those which I consider verging on obscene, I refer to the male underwear ads which are nothing more than a vehicle to advertise the male genitalia to pander to a certain type of man. I am particularly frustrated when watching lunch time American news the breaks which occur toward the end and show no more than a few seconds of the broadcast before another ad break. I CAN ONLY SAY TO THEOSE RESPONSIBLE AT SBS. STOP AGGRAVATING AND ALIENATING YOUR FUNDING SOURCE
Although I find the ads disappointing and invasive I still value highly the range of programs offered by SBS. For me, the ads are such that I go and do other jobs while they’re on. I agree very strongly about gambling ads. On the other hand I also note with interest the number of ads with an humanitarian focus presented to SBS viewers. What can SBS do – the facts are that the Federal government has little sympathy for public broadcasting in general and has little interest in the views of a multicultural population.
It is nothing but Orwellian brainwashing on a scale never before historically seen. Its purpose is to turn viewers into consumers who will never be satisfied; servants of the endless greed-driven consumption that is destroying the planet. Its frequent use of childish message simplicity belies the sophisticated understandings of human behaviour that effective propaganda utilizes.
Emotive reactions are the vehicle that suppresses real thought. Even the very programming itself is in service to the smorgasbord of mind-numbing messages invading the nations living rooms, unasked for, on consumer paid-for gear.
It is utterly outrageous that commerce could be granted such licence to ideologically brainwash in the service of consumption.
Great service spoiled by repetitious and frequent advertsj
I agree there are too many ads and anything to do with gambling should be banned across the board.
It’s a hidden agenda to remove all free to air tv, to make sbs impossible to watch through so many ads and poor shows.
Sport gambling ads are morally reprehensible and show total disregard for negative impacts especially on children and teenagers.
https://www.psychology.org.au/publications/inpsych/2013/june/gambling/
https://aifs.gov.au/agrc/publications/sports-betting-and-advertising/impacts-sports-betting-advertising
I have rarely watched SBS since ads were included in programs. In some years I have watched nothing to avoid the irritating intrusions to a program that ads are.
Like many of the posts above, I too record the programmes I wish to watch, and FF through the ads. Another option is to watch ON DEMAND, where there seem to be fewer ads.
Together with the ads came the fall in quality. The mediocrity of some of the presenters makes you think WHAT IS REALLY GOING ON?
Too hards to watch anything. I totally ignore the ads anyway even if I did watch. However, I don’t watch SBS because of too many ads. Same as commercial tv, just can’t watch it.
SBS used to be one of the greatest channel with a remarkable diversity in programs until few years back when Advertising started and ruin it for us spectators, sad to seen it become just like the other commercial channels, boring and frustrating, so i dont watch it much any more as adds put me off.
I can’t stand shouting commercials like the harvey Norman commercials
Too many gambling ads – would like to opt out of those for trigger reasons (especially SBS OnDemand).
Ads are fine for filler, but have a timer with a block of say three-five minutes of ads so we know what we’re in for and can either go do something else or focus elsewhere and leave it playing rather than missing the program.
Get rid of ads, I find them irritating and banal. Ads disrupt the flow of otherwise good programming.
It’s a tragedy, good programs are unwatchable because of the the ads. So many of us have turned to other streaming organisations (Netflix etc) because sbs ads destroy any viewing pleasure! Now it appears sbs is showing more than allowed. It’s no surprise, I’m one of many who’ve given up on good programs.
I agree with all the comments above – gambling ads unethical, far too many ads and repeats in a single break. Most are tedious and badly made. Some promote antisocial behaviour. And breaking up programs too often- not in a natural break. Revenue from Facebook and Google should go to SBS and ABC. Perhaps that way SBS winter not need advertising revenue.
The advertising on SBS on Demand is frustratingly spaced and prolific and almost always causes the Internet program to freeze whilst the screen has to refresh when the advertising starts. Very inconsiderate to viewers and makes me want to ditch the service.
Watching catch up programs or series is a pain with adds.
You can never fast forward without an add despite having watched one minutes earlier.
We find watching SBS on Demand very difficult because the transition to the ad break often gets ‘stuck’ and we can’t get it to move forward. The ads themselves are often repeated immediately and are much louder in volume than the actual program. They really grate. And they seem to occur every 5 minutes, really disrupting the flow. It’s frustrating because there are so many good programs on SBS that we want to watch but the frequent ad breaks are a real disincentive.
We always mute the ads and so something else during their airing time. They mean nothing to us
I rarely watch SBS these days. Because of the ads.
Far too many Ads and gambling ads should be banned, not only on SBS, but all broadcasting.
SBS should be ad free.
I found the nature and volume of ads appearing on SBS becoming so intolerable that I stopped watching it about two months ago after many decdes of loyalty. How government-employed management could act so irresponsibly and uncaringly towards their loyal viewers is something I would blame on the government itself from the PM down. Unforgivable!
It is annoying that SBS has to have ads at all. Too often the flow of programs is disrupted by ad breaks. Government think they can save relatively small amounts of money by cutting funding to public services like SBS and ABC. These saving could be ofset with reductions in “government enquiries” which cost millions, take years and reach no conclusion/are ignore by government.
The ad breaks on SBS seem to be set to occur after a set time with little consideration of plot disturbance, often breaking in mid way through a scene which has to continue after the ads
I have contacted SBS about the frequency and positioning of ads before. Ads are way too frequent. When live streaming an ad is the first thing the viewer sees instead of the program, which is annoying and disruptive. With On Demand ad breaks are frequent and then stall the program being viewed, meaning you can’t go back to it without starting from the beginning. I also resent having to watch numerous ads if I fast forward through a program. SBS has definitely lost its way and is falling prey to advertising dollars to the detriment of the service.
Our public broadcasters (both ABC & SBS) are under enormous financial pressure due to significant reductions in federal government funding. My impression as a viewer of both live TV and streaming programs is that there are too many ad breaks, that they do not fit “naturally” into the narrative structure of programs, and often are too repetitive – especially in streaming programs where the same ads are frequently repeated back-to-back. I also resort to the MUTE button. The ads are a turn off and the issue of funding and advertising needs to be addressed more strategically and creatively the Board and Management of SBS.
Corporate run commercial TV is why we switch to, and love, SBS. Leave it neutral and clean of financial persuasions!
Waiting for the endless string of ads to finish during the 6:30 pm SBS news was SO frustrating I changed channel!
Couldn’t agree more with many of the comments above. SBS is as bad or sometimes worse than the commercial channels. Thankfully the content is of a higher quality (generally) otherwise we would not watch it at all.
Sadly, the number of ads is making SBS almost unwatchable.
Too many ads, especially ads which are not community minded (eg gambling and fast food)
the frequency and repetition of ads puts me off watching SBS.
Ads on SBS should be limited to between programs not during programs.
Love SBS except for the constant breaks with the same repetitive ads, often with the same ad twice in one break.
Advertising, the art of deception, the cancerous scourge infiltrating almost every aspect of the modern world.
My TV has been banished and replaced with a music system.
Sure the ads are a pain but so are all the programs and promos about white middle aged trainspotters, royalists, and WW2 fans. This isn’t SBS Charter content.
Not so long ago the quantity and type of ads on SBS was rather high but you had the thought “oh well, I’ll just have to put up with it”. More recently the time given over to ads has grown to a ridiculous extent. Even worse, the type of ads is degrading the channel. Specifically, gambling ads should never be allowed. Gambling is a major social problem in Australia and the number of ads to which everyone is exposed on a public channel is reprehensible. Get rid of them. And turn down the volume. We don’t need ads played at such higher decibels than the main programs.
If ads are mainly to increase revenue, why are so many ads for SBS repeated over and over and over, unnecessarily? SBS is not designed to make money anyway. It is a public service.Keep well.
Too many ads disturb otherwise enjoyable programmes
Stop the gambling ads altogether. It actively promotes a cruel mental disorder that is crippling our community- surely in opposition to what social programming is for
Oh for the days of advert free SBS
“Unacceptable ad breaks on sbs . Distraction take us away from the broadcaster to othe platforms. Multicultural Australia is the poorer for the commercial intrusion in our leisure time . More funding is needed otherwise commercial interests will further erode our culture and particularly encourage further inequality.
With SBS advertising, I flick the mute button or check out what is offering on other channels. Sometimes I am more tempted by what is on these other channels, especially the ABC. Generally I can’t stand advertising.
There are so many advertisements now that it makes me not want to watch. Is that the idea?
Loved SBS when there were no ads!
Disappointed when they were introduced but they were inbetween programmes so they were tolerable, given they could be muted. All Ads and promos should be in these spaces and not cutting up content. I no longer watch SBS live because I can’t stand the ads. I will watch on demand if there’s something I particularly want to see. I’d be happy to become a ‘no ads/promos’ subscriber so that viewing is a pleasure instead of a constant annoyance. I pay for other TV content for this very reason
SBS ans ABC- far too many self promos
There definitely too many advertisements – should not be any – proper funding is required.
Also the SBS app is appalling! Trying to find where you are up to with a program that I’ve part watched but maybe got called away ect is dreadful. I end up having to watch sometimes the same add group 3 or 4 times!
I hate their app and avoid watching it to catch up if I can!
The many ads interrupt what would otherwise be an enjoyable watching experience
LNP government intent on killing our Public owned services. Save our information services remove this dubbious government.
By The People
For The People
Not
By the government
For the wealthy.
I find these breaks not only frustrating but they abruptly interrupt awkwardly, almost mid-sentence, without any attempt to use a natural break. Programs are normally excellent but are spoilt by constant advertisements.
SBS is a national treasure. As a Media teacher, I was extremely disappointed when advertising was introduced on this channel which previously gave viewers some respite from the abrasive presence of commercials.
When I studied screenwriting, I learned that some TV programs are written with ad breaks in mind e.g. soap operas. However most visual media are constructed without breaks as it is important to keep the viewer engaged.
Please remove advertising from SBS or at least minimise it so that it conforms to the regulations and is intelligently placed where it will cause least disruption to viewers’ enjoyment of programs.
SBS On Demand was a good alternative to avoid the annoying ads. Now they have forced us to turn off any ad-blocking and are streaming the commercials. I feel force fed, although I barely take notice of any advertising content. A waste of my time.
The ever-increasing ad breaks on SBS and even the promos are becoming so intrusive. SBS used to be an excellent source of quality news and programs without being the subject of people trying to create desire and turn me into a consumer of their products. Until the neoliberals got their hands on it, that is, and as with everything else they touch, turned it over to the market and commercialised it. What a crying shame. No escape from being bombarded with appeals to be consumers of commercial products that I don’t want, trying to create a desire to buy useless luxury goods, when what we are really here for is to be informed and to watch quality television. There is no escape. I turn to SBS for quality television, turned off by the ad breaks and promos. This is supposed to be a “public broadcaster” but the neoliberals have ruined it! Get commercials off our public broadcaster!
There is no need for SBS to constantly promote 1,2 or 3 of its own programs during commercial breaks and the number of breaks has increased dramatically since the station started airing adverts. This makes watching programs extremely annoying as there is no ‘natural’ place for ad breaks. Two advert breaks per hour is sufficient disruption for any program though ideally only having adverts between programs should be the goal of the station.
I love the programs that SBS does … but I think they are diminishing in their efforts to ‘support the good in our society’.
I don’t believe that a public broadcaster should be contributing to the advertising of products that are detrimental to our health and to the good of society. I target gambling, and alcohol as being products that cause great damage to our people; are expensive in health costs (physical and mental) and increase the level of violence within communities.
With so many Australians contributing their support to members of the community to survive and prosper hopefully, I take great exception to the advertising of products on SBS that are contrary to supporting the best in our communities.
SBS is supposed to be shining a light on the goodness of mankind through programs that inform, enrich and delight … not exploit and corrupt … for the financial benefit of corporations that exploit the already marginalised in our communities …. VERY DISAPPOINTING!
WE almost never watch SBS live to air because of the breaks to program cause by ads.
Why is the federal government not funding SBS so it wouldn’t have to rely on so many ads and promos that totally spoil the viewing experience? We need a public-funded and independent TV including a multicultural channel. This privatisation has been disastrous to the point that we hardly watch SBS now. There are plenty of commercial TV stations if you want to have a program disrupted time and time again.
The advertising on SBS is now absolutely excessive. and often. the same ad twice! Fair go SBS!
It’s the promos on SBS On Demand that puzzle me. They’re not paid commercials, just repeats of in-house promos. They break into the program at any random moment (often mid-sentence) in the most clunky and amateurish way. They are not earning money for SBS; they are usually only 30 seconds long, so no good for making a cuppa; they are not there to make up time since this is an on-demand service. Why are they there, Mr Taylor? Why?
Sadly SBS has become like another commercial station but the gambling ads are the hardest to sit through. Bring back our old SBS!
You all know the Mad As Hell intro….that’s me watching SBS! But not as much as I used to.
If the SBS intentionally wants to kill off their business, they are doing a good job of it.
It seems to me that both the ABC and SBS are being systematically destroyed.
I usually watch SBS On Demand rather than the channels. No ads.
I am particularly upset to see so many ads promoting gambling and junk foods on the SBS channel. Please, please stop!
SBS and ABC are my two favourite channels. I rarely watch SBS now because of the excessive number of ad breaks during programmes. If we must have ads and promos – excluding gambling ads which should never be shown – put them between programmes, not during the programmes. This was the policy many many years ago and I thought ads were a good opportunity to go for breaks between watching. Not any more. The worst thing is the ads in streaming programmes. They prevent me watching excerpts unless I go through all the ads.
I really don’t see the amount of advertising on SBS as intrusive. Sure, it was better in the old days without ads but the fact that the government keeps trying to strangle both SBS and the ABC by cutting funding to them is forcing SBS to have ads to pay for services and programming.What I consider is overkill on advertising are the amount of ads on channels 7, 9, and 10. Viewing these channels is nearly impossible due to their ever increasing ad rate. Good on the ABC for not advertising during the running of programs but they have also cut programming and staff to cope with the issue.
Too many Ads and Promos AND too many train journeys nearly every night on SBS 1 … what is this about?
We need to have something very particular to watch SBS now, as there are far too many int eruptions.
We also avoid SBS on demand for the same reasons.
Its a pity, as it used to be our only other place we watched TV other than ABC.
We hope they can be reduced.
Ads are very annoying and disruptive to the programmes, especially on SBS On Demand where it should be completely eliminated except at the beginning of a programme. My strongest objection is for ads for gambling; ads for tobacco have been banned; ads for gambling g and alcohol should also be banned.
I took issue with an ad that showed a person cutting documents with a electric saw
and another person shredding documents with a blender with the top off.
I reported this gross misuse of appliances/tools, which would be contrary to workplace H&S rules and practices, to SBS and to Ad Standards Aust. Their response was that from the Ad Agency:
HE ADVERTISER’S RESPONSE
Comments which the advertiser made in response to the complainant/s regarding this
advertisement include the following:
Our firm appreciates the role and concern of the Advertising Standards Board and
recognises that a consumer complaint has been received. We appreciate theopportunity to respond, however, the opinion of our firm is that the TV ad in question
does not contravene Section 2 of the AANA code of ethics.
and from the Ad Standards panel:
The Ad Standards Community Panel reviewed the advertisement and considered your
complaint at its recent meeting. We have to advise you that the Community Panel did
not uphold your complaint.
If we must have ads can SBS ensure that the same ad is not repeated several times especially sometimes during the same break!
Not only are the ads disruptive to the program but they’re invasive. As for gaming ads, I’m disgusted and don’t want to be inflicted with gambling of any kind. It’s dangerous!
In my opinion tax payers are entitled to know what is going on.
I find myself unable to evade the strongest suspicion that in my view the management of SBS is incompetent. I hope not corrupted.
One of the strangest things is the amount of program time time wasted by ultra repetitive promos — so repetitive they become highly aversive. I can’t think of any explanation for this other than gross incompetence or deliberate sabotage.
SBS TV has been so degraded by non program material that unlike formerly, nowadays I seldom watch it.
Last night while viewing on SBS a program I wanted to watch I turned off the TV because I could not put up with the adds & promos.
I have come to appreciate a lengthy break during viewing from 7-9.30 but not so many.
The repetition of ads is maddening. Yes, we got it the first time! It is very wrong that our governments do not fund public broadcasting properly. Why ever do we not have a national lottery to help fund such good causes? The British one supports many wonderful cultural productions.
Not only the number of ads, but the repetition of the ads – especially promo ads. Why do we need to be told about an upcoming SBS program 17 times in the one hour??!!?? Totally ridiculous.
Also, the foreign content of SBS programs has become heavily skewed towards US content. From US cooking shows (appallingly bad and unhealthy!!) to news (totally boring and irrelevant) – 8 hours of Trump per day is far too much for anyone, and as for Biden or the US elections – YAWN!!! Change channel!.
SBS is only a faint shadow of what it was becoming 20 years ago. Gone is the vision of Asian internationality; China is only portrayed as a bogey-man, Eastern Europe only gets a mention at World Cup, Eurovision or TdeFrance times. The world has shrunk to the USA and its allies.
SBS needs a total revamp. Because of the weight of US content available on commercial channels, I would like to see SBS become USA-free as a first step towards correcting the balance. It needs to become truly a-political and more concerned with compassion and mercy, as a correction to the violence and abuse so heavily flogged on commercial networks. We need a truly SPECIAL Broadcasting Service.
Further to the complaint, SBS did not reply, but did seem to remove the ad from breakfast period and at other times for a few days.
The number of ads makes some programs almost unwatchable but the repetition of promos, even for programs that are weeks off, is mind numbing.
The worst thing about the adverts is they are so repetitive and while watching one program you can be interrupted by the same add several times and often back to back(which is even more annoying) Why would you begin the SAME advert again just after showing it ? Worse still the adverts seem placed just at the moment of tension or suspense during the movie or episode.I think adds are best placed just before the program begins and just after it and if you must place ads I guess one in the middle is acceptable ,but that is all.
With so many viewers loathing ads, how can they possibly be effective? Certainly a turnoff for us. Even the ABC has excruciating cross promotion of programs. STOP aiming for lowest common denominator.
Many ads before the end of Tour de France!!
I hate gambling ads and ti hate he way Lots of ads scream at you for attention. Like many others, I record programs so I can skim past advertisements.
SBS was my favourite broadcaster until they started with the excessive advertising.
I find the frequency of ads disruptive to my viewing pleasure.
Get rid of the gambling advertising.
It was a sad day when SBS was forced to air ads. Initially this was restricted to in between programs, which was bearable. But now it is totally disrupting viewers pleasure. We rarely watch commercial channels because of the advertising and SBS is now moving into that arena too. Only its superior programs have kept us tuning in, but that won’t last as we move to online programs more and more. SBS should be fully funded.
The ads make me so angry that I will not watch SBS in real time anymore. I prerecord and fast forward the ads when I watch the recording.
I understand that SBS needs to generate funds but why not have the ads before and after the programs.
Can’t we go back to having the ad breaks between the programs? The increasing interference is making SBS unwatchable.
Anne Cameron
Please ensure the SBS continues to provide the excellent coverage we have come to expect BUT without commercials. I am willing to pay for this service as it is one of the two channels we actually watch. Both the ABC andSBS need to be commercial free, they are essential services to our nation as demonstrated during this past horrific year.
We are choosing not to watch SBS because of these ad breaks. A pity really. Many breaks are just so repetitive (same ads) and are timed to break the flow of programs at critical moments. How pathetic. Also it is obvious the volume goes up during adds. I would be happy to pay for On Demand stuff.
And whow can we thank for starting this, Little Johnny Howard. What a towing intellectual he is.
Advertising is poisonous, nasty and unpleasant. It makes SBS unwatchable and I am no longer able to watch it except where these appalling advertisments avoidable.
In general there are too many ad breaks, with in-program ad breaks being the most inappropriate and annoying.
It’s irresponsible to have gambling ads.
Please no gambling ads
SBS has a role dictated by a charter and should be adequately funded to do this.
In our house we are missing quality programs on SBS because we find the ads too disruptive. Our annoyance results in advertisements having a negative effect. Once we were devoted SBS viewers but now we watch SBS World News only. Can we only dream of adequate government funding for SBS?
I especially object to the subject of many of the ads; and, at times, the presentation of those ads. SBS produces outstanding content, interrupted by too many poor quality advertisements.
Way too many repetitive adds and promos inserted into program run time and it is self defeating as I simply turn over to another channel or mute the sound and ignore the dross if I haven’t recorded the program and skipped past the muck being shoved out.
It’s not just the fact that adds are played in program run time it’s that they insult the makers of those programs. I liken it to having some ‘fuller brush man’ knocking on my door every 15 minutes, and that would get a very brisk EFF OFF.
F–k the ads!
SBS has become almost unwatchable with the number of ads and promos. Went from a favoured broadcaster to a hated one because of the excessive advertising and promotion. By the time a promoted program is aired one is so thoroughly sick of the promo there is no wish to watch it. We no longer do.
Advertising needs to be culled big time as it is affecting the quality of SBS TV. Makes me want to tune out, instead of tuning in.
Apart from news I now only watch SBS programmes that I’ve pre recorded. This enables me to skip the ads and promos but it is annoying and disruptive. There’s no clear demarcation to re introduce the programme I’m viewing.
I am visiting from the US, even though australian. SBS is a breath of fresh air in a stale media environment. Along with the ABC these networks should be cherished and fully backed as public necessary items. Essential to keeping the bastards honest and the people well informed about the world and Australia. Re-instate funding, otherwise this country will end up just like the US with no public media and an ignorant population, easily manipulated. I don’t think most Australians realise just what they have got in the ABC and SBS. Jems!
I watch SBS on my computer and all the ads chew up my downloads.
Having answered in the affirmative to the three questions, I acknowledge that the problem lies in the cuts to funding that have been applied by Coalition Governments. They have an ideological hatred of the ABC & SBS. Pressure has to be brought to bear on them. But good luck with that. They have a tin ear in such matters.
Too man
y ads
Far too many ads and worst of all, Gambling advertisements! Unacceptable for our public broadcasting service.
Because of the excessive and frequent advertising I now record my favourite programs or watch SBS On Demand, Still the best free to air channel, with the most reliable news programs – long live SBS
Besides the fact of there being too many ads on SBS the positioning of the ads within the programming are awkward and annoying!
I generally end up turning off the tv as I get so frustrated by the advertising!
Please bring back our ability to watch great content without the insult of the constant ad breaks!
If the ads were run at the beginning & end if would be very much better. Most of us don’t watch them anyway. Interrupting programs to run your own promos is infuriating.
SBS was supposed to be commercial-free. MUCH prefer it that way.
Hate the sneaky ways of showing ads by banner runs near station logo and condensed scrolling of credits (I often want to find out cast and other production details) on split screen so that promos and ads can be shown at same time. So annoying that I will read a book instead!
So frustrating, so sad that SBS is now so irritating to watch. Like some others here, I would prefer that ALL ads are screened on a half-hourly basis or less – I seem to remember that when SBS first went commercial, we could actually see a complete program UNINTERRUPTED by ads! However, I don’t believe that SBS should have to rely on commercials at all, and the frequent repetition of so many does no more that encourage me to AVOID the products.
And surely we don’t need quite so many repetitious and therefore boring promos either!
The repeats and quality are such one would conclude it’s only to force viewers onto the commercial channels as an escape.
Please, please at least stop the gambling adverts. Gambling in Australia is as destructive and pervasive as guns are to America.
The main reason that I only rarely watch S.B.S as I refuse to watch ads
Watching the World News now with self promotion adds constantly, make it so frustrating that I go from ABC to SBS and then stick to the ABC to watch the rest of the news.
SBS should be fully funded by the Commonwealth Government, and should not need advertisements. It is a Special Broadcasting Service for the publc.
I used to watch SBS streaming dramas, movies, etc., but do not use it any more because of the excessive intervals/breaks for advertising. I cannot fast forward through the breaks – very annoying!
I’m not unhappy to have ads before and after a program, but program interruption for ads is a no-no.
SBS is essential, ads or not.
The now excessive number of ads on SBS destroys the excellent dramas particularly.
Flow and tension of a drama is broken.
Very disappointing. If ads are essential to the financial viability of SBS what happened to the idea of placing ads at the end of programs ?
And why gambling ads are allowed confounds me !!!
The same ad is replayed numerous times for one show, drives you insane, totally unenjoyable.
I don’t mind the ads. There are far fewer than commercial stations, and I use the time to fetch a cup of tea/wash up etc. It’s healthy to have something that forces you to get up and move away from the TV several times an hour.
If the alternative is fewer programs with local content, fewer interesting series because there’s not enough funding, then I say keep them. The only thing I would suggest is no ads that shout at you (eg Haggle etc). That forces me to mute the TV, then I always miss the first few minutes when the program returns.
Unfortunately, our lives our governed by business models largely about increasing profits! And the excessive time used on advertising on SBS exemplifies this. Who is the SBS really serving?
With the current conservative war on public broadcasting it is not surprising to at least suspect that a campaign to annoy, disgruntle and finally enrage SBS viewers is in full swing. This is easily achieved by regularly providing frustratingly ill-placed interruptions to programmes. Ultimately, the apparent aim here would seem to be to so enrage SBS viewers that they abandon the channel altogether and so provide ‘justifiable’ grounds for its sale to commercial interests.
Heigh-Ho, another petty ‘triumph’ for neo-liberalism.
Why not go back to charging the public a licence fee (or something) and dump the advertisers altogether?
Let the commercial stations have the ads & return sbs to its original form.
I would really like to see the public funding of both SBS and ABC, as there are already sufficient platforms for commercial advertising. More than enough. Ads invade out lives as soon as we access any internet service, including in-app advertising in games for children, there should be some respite, and public broadcasters preform an important function outside of this heavily biased world of commerce. SBS on demand has the most annoying repetition of unwanted ads, as soon as one finishes , the same one immediately runs again, and again.
I have noticed a significant increase in advertising and promos on in the year on sbs. It’s like a commercial channel.
We have been avid viewers of SBS since it’s inception. However we have been recording programs since advertising started and these breaks even in recorded programs are becoming longer and longer to get through, even on fast forward. The program guide will say the program takes 90 minutes and yet it will only really be 55 minutes. The rest is ads. Gambling ads should not be shown. What a shame that this once wonderful channel that welcomed news and entertainment from across the world should be so debased.
While I agree there are too many ads and promos, I think SBS has fantastic documentaries and dramas. The evening news bulletin is far superior to the ABC’s as there is much more international news. If funding has to be raised this way, so be it. I would not want their programming to change. I find the ABC’s promos and songs even more irritating.
SBS, you have lost me due to the constant interruptions to programming.
I can’t stand how SBS Ads interrupt important moments in a program, completely unstructured.
I rarely watch SBS because of the ads and promos, unless there is a program I really want to see (and even then I often tape it)
Would prefer just a long ad break at the end which includes promos for your SBS shows. No gambling adverts ever and minimal junk food please. I mostly watch ABC with no ads now.
The greatest deception of our times, marketing! Treating us and addressing us like we were mindless mugs, as we should all feel the same, suffer ailments, in the same way, having to have the same desires, the same needs and wants and hopefully believe in the same nonsense, or better be equally ignorant. It just makes the production planning so much easier, and you don’t even need to have a communist-style dictatorship when apparently “everyone” used to want what the system told them to want. What is the difference here? We are just using more colours and seductive voices! The disturbing thing is the punters get sucked in, having forgotten their individual desires.
Did not the original legislation restrict SBS Management to commercial breaks at the beginning and end of programs ONLY?
SBS makes a most important contribution to Australian media. It should be funded by government and advertising should end. The cost to the taxpayer is tiny in terms of the money spent on SBS as a proportion of government expenditure.
Dear SBS, you have some of the most interesting and excellent content from across the world to watch. Yet, the formula of ad breaks has made tuning to any show unsatisfactory and has lead me turning off SBS. I think twice about watching SBS. Its a deep shame and unsustainable for us viewers who want to engage with SBS. You are alienating viewers. I don’t watch SBS for the ads,I watch for the great content.
My wish is for a better flow of programme viewing with less ads.
thank you
Advertising is not consistent with SBS’s mission and advertising of gambling is immoral.
Please return our SBS to its original and legal format.
Ads denote commercial information and commercial or other interests whether it’s for private organisations here or overseas or SBS itself and those interests expect to receive some return. Like Belt and Road arrangements there’s always a return expected which may not be in the original plan and is open to manipulation.
These forces seen and/or unseen, have the potential to operate outside SBS even possibly outside Australia diverting our wisely created original positive benefits for a socially integrated, equal and happy society from SBS to less positive results. At this time Australia was known worldwide as a most successful model of positive integration of a large migrant population.
SBS was created by the Australian people with our taxes through our Government representatives to harmonize our large new migrant population providing TV programs to their interests and needs. SBS was originally wisely designed for successful integration and it’s positive charter should not be overtaken by the interests of commercial and/or other entities.
Finally the SBS is being used for such things as gambling advertising which is very far from SBS’s original successful concept of operation. Certain sections of our new population are particularly susceptible to gambling and find this encouragement to gamble destructive and anti social particularly whilst settling into their new country. Our wisely organised SBS has had its original charter diverted towards a negative outcome.
Our SBS created to particularly assist and include migrant assimilation was strongest when it was free to do so uninterrupted by ads a day their resulting forces and interests. Stemming from this came a greater knowledge and international understanding for all Australians and positive image for Australia throughout the world.
Through our elected Government representatives directing our taxes to benefit Australian society on the Australian people’s behalf SBS helped create a happy egalitarian environment the envy of the rest of the world for social acceptance and successful integration of large numbers of migrants. Thus promoting our national characteristics in a positive and beneficial manner worldwide.
Too many adds and too repetitive e
SBS has really good programs but I rarely watch them because of the advertisements
Both SBS and ABC require large, increased public funding so they can serve our community well.
There are definitely too many ads. SBS is not just another commercial station. Gambling ads shouldn’t be allowed anywhere.
Sometimes it is hard to tell if it is an ad or part of the program, really confusing with no natural break in the program, and then the same ad repeated again within the same break.
Lets keep our SBS without an oversupply of advertisements!
SBS is NOT a commercial network. Leave it as it was intended to be – ad FREE!
The less intrusions the better please!
SBS is a necessary part of life and a welcome refuge from the hype of commercial tv. which treats viewers as morons
Gambling ads are disgraceful and no amount of “gamble responsibly “ will stop it expanding with such frequent airing.
I look to SBS to give me good quality viewing and to be treated like an intelligent person, using proper grammatical English, not the Americanization style which is changing the language our younger generations are using.
Our public broadcasters need proper funding so they can provide the service they are meant to.
Too many ads at present disrupting shows we want to watch. Leave the ads to commercial channels.
I enjoy watching ABC and SBS because there are fewes breaks, but lately there are so many adds on SBS with gambling and double-ups and promos in the same break it’s hard to consentrate on a great movie on 32. Please, give us isolationists better viewing.
As so many others have commented here, I watch SBS less and less these days, not because of the lack of quality programs but due to the unceasing, intrusive and frequently inappropriate advertising that now appears to be standard operating procedure. Importantly, at a time when many Australians are in difficult financial straits it’s totally irresponsible to be promoting gambling at any level and I’m also tired of the endless ads for life, funeral and other insurance interrupting mid program. If viewers want this information 99% would be quite capable of searching out what they need to know without this constant prodding by commercial interests. If SBS (and even the ABC) doesn’t take notice of what its viewing public is saying, then perhaps it will simply devolve into one of the dreadful commercial channels and we’ll be left with no quality television and no choice whatsoever – what a sad day for Australia. I would be happy to pay a fee (similar to Netflix) if it meant that we could be spared this incessant bombardment which has turned SBS from the quality station it once was into an endless stream of advertising with the actual program awkwardly slotted in to suit the advertisers. Thank you for providing this option for comment so that SBS can begin to understand what viewers really think – now if only SBS will listen and act we’ll all be better off.
I understand the commercials were introduced on SBS because of Government cutbacks. The frequency and quality of commercials reminds SBS viewers of privatisation taking over another successful public asset.
I understand that television services cost money and have to be paid for some how. If the government does not see a need for a multicultural broadcast media then maybe SBS has a responsibility to fund itself in a way that fulfills its’ Charter & it sees as legitimate and appropriate. Have not been watching as much television since the advent of Covid19, have developed other pastimes and its has been citrus season so have been making marmalade!! I police my watching, using a TV weekly guide to plan, watching mainly documentaries, not just room filling eye fodder!
Bad news, however comic from some quarters I find depressing so have been limiting my exposure, my mental health is more important.
Must say I totally agree that the betting ads are inappropriate particularly at a “family viewing” hour.
Shelagh Kemm
I agree, too many and inappropriate ads reflecting the Coalition campaign to defund all that’s good about Australia.
No gambling ads. See that same one for sports bet over and over. Tried watching The Salisbury Poisonings live to air but had to switch to streaming because I couldn’t stand the frequency and length of “ad breaks” on live to air, much better when streaming.
It is a rel problem when streaming ones TV, Can’t escape the adds one is even told how many and the duration.
The adds are so repetitive and so many breaks interrupt the f programme so that it becomes difficult to follow the story line. Special moments can be missed when watching a live event
WE understand that revenue must be raised somehow to keep SBS operating, but the number and repetition–especially for their own programs–is so irritating as to make one turn off, and especially, not watch the program being constantly promoted. The same ads, repeated ad nauseam, is a pest and enough to make one flick channels to something else! Worse even that the so-called commercial channels.
Hi my last comment would have sufficed please put your ‘post comment’ box under the final move I was spam botted – now you’ve l o st my comment!
I have started to no longer watch SBS because of the ad breaks, worst than Commercial TV.
It’s just no longer worth it.
SBS is a Service Company, it is paid by the community and should be aware of its first obligation to its public, who are its owners as well! By all means, allow ads to help the service but be cautious about the greedy aspect of this by your staff.
Despite the excellent content on SBS, I find myself avoiding watching SBS due to the frequent interruptions., which seem to be ever increasing. Given the choice of streaming services now available to me, I’ve migrated across from my once favourite SBS for options that entertain without irritating me with constant interruptions.
SBS used to be a great channel but nowdays I don’t watch it at all due to the commercial breaks. It’s a pity as there is some great content. Same applies for the streaming app…
Oh for the old days of SBS! I often give up on watching a programme now because the ads are too frequent, too inappropriately positioned and too stupid.
Sadly I don’t watch SBS at all anymore because of the ads. I wish I could watch it.
Wouldn’t the complaint be better directed at the funding body – the Federal Government?
It is pretty clear that the reduced funding for SBS and the ABC is causing a deterioration in the quality of these two crucial sources of reliable news and quality programs, and both are under threat from the current national government policies of cutting funds to valuable public assets and privatisation policies.
My biggest problem is not the ads per se because I timeshift most programs. The pre and post break supers and graphics really annoy me. They often interrupt the flow of a program as much as the ads.
More program content and less PLEASE!
Along with the ABC, SBS needs more government funding, not less. Ads often disrupt my streaming service and the program gets stuck there. We used to only get advertising before and after a program. Would be great to revert to that.
What happened to SBS ? Once upon a time and not that far back, it was the TV channel to watch. Now, it’s become unbearable to follow and stay tuned because of the frequent and nonsensical advertisements. I would prefer to stay with SBS but it’s a hard act to follow. Netflix is a very attractive alternative simply because I’ve found the joy of watching documentaries, series and films without interruptions – that used to be that way with SBS. Some advertising is OK but like all else, with moderation and discernment.
Due to the ad breaks I’m now reluctant to tune to SBS. This is a real shame since SBS has the potential to be much more user friendly than it now is. What really gets my goat is the icessent annoying repetition of the same ad during the interminably long ad breaks. I just switch channels at that stage!
I hate the gambling ads on any channel. SBS used to be such a good alternative channel to ABC, offering great multicultural content and now they’ve spoilt it with all the ads and promo breaks in transmission. Give us back our original SBS.
In our overly commercialised world where marketing and hype have become the mainstay of our society, how refreshing it is being able to watch programs with an uninterrupted train of thought – as on the ABC and as once was on SBS. Please have our public broadcasters be a model of civilised living in the Americanised, loud, and short attentioned world we have to endure. STOP ALL ADS on PUBLIC BROADCASTERS!
There are too many ad breaks on SBS. The repeated ads are especially annoying. Sometimes I just mute all ads. I tried to put in a complaint but the process looked too complicated and gave up.
Actually the ads have a reverse effect on me. I go out of my way to not buy one of the products as I am so irritated with the anodyne advertising. Films in particular, should be sacrosanct and a moment of huge drama suddenly split by an adult peaching health insurance. I used to value to overseas news as I work mainly outside Australia.. but even that pathetically thin, making way for football and other sport. Can those of us who resile from sport also have an untainted station?
ABC and SBS are essential public services that should receive adequate public funding. Dismayed that the SBS now has to run advertising.
Some programmes are so broken up with advertising the continuity is compromised. The same add over and over during a single programme is very tiresome. Gambling adds really!
if the various governments stopped reducing the funding we wouldn’t need them, but if they are a necessity then let us go back to the original placement of ads, in between programs
SBS is forced to advertise because the current federal government continues to ‘defund’ it.
Advertising on the multicultural SBS should not be necessary. Originally it was solely funded by the federal government (I think that is correct).
I watch SBS for international news that is not covered by the commercial TV stations.
SBS PLEASE remove all gambling advertising.
SBS needs better funding.
Actually the ads have a reverse effect on me. I go out of my way to not buy one of the products as I am so irritated with the anodyne advertising. Films in particular, should be sacrosanct and a moment of huge drama not suddenly split by an adult peaching health insurance. I used to value to overseas news as I work mainly outside Australia.. but even that is now pathetically thin, making way for football and other sport. Can those of us who resile from sport also have an untainted station?
Edited copy
The advertising is way too frequent and also cheap and nasty. It’s like watching a secondary commercial channel after midnight. Dodgy repetitive insurance, continence products etc
If you’re going to have advertising then have some pride in getting “decent”, creative advertising that might even relate to the program. And don’t assume that your audience all need continence products, or aren’t intelligent enough to already have insurance, or never buy cheap and nasty insurance off a tv ad.
I don’t want to order underwear on line, hear about products to get my joints mobile or order funerals or insurance with just a phone call.
I might be inspired by travel ads, new food/beverage products, coming festivals, events, even animal care, environment care ads.
If you’re going to advertise go back to your charter of frequency and take some pride in getting some quality ads.
The only ads that seem to fit in suitably are with quiz shows and cooking shows, where info assumes they are created for both public broadcasting and commercial formats.
You can do better. So much better.
Obviously the government cutbacks have caused the necessity of commercials, however the plethora of cross promotion exacerbates the situation and needs to be limited.
I agree that SBS has lost a lot of interest as a result of excessive adds. The SBS has always had a marvelous role in looking at countries outside of Australia. No other Australian network specifically does that. OK, so they have to make money to spend on new programming and government is constantly cutting funding to SBS and the ABC. If adds have to be included for additional revenue, how about doing what some other countries do and put all the adds in one sector at end or beginning of a program.
Thank you for the gathering of such detail. The day-to-day experience documented and the outline of some efforts to bring these concerns of the viewing audience to the awareness of the decision-makers and managers is great work.
I add my opinion that Both commercial and SBS self-advertisement ( program alerts) have become too intrusive.
The SBS should have been kept free of commercials.
Please continue your efforts for the provision of a truly multi-cultural, Australian-informed broadcaster, as was/is what I expect the SBS to be.
The commercial ads and promos on SBS are repetitive and immensely disruptive. Ads promoting gambling shouldn’t be aired; there are ethical considerations in promoting a potentially destructive, addictive activity. We are great supporters of SBS but resent the increasing number of ads. Given the role SBS plays in multi-cultural Australia, increased government funding would seem reasonable.
Yes. Please give us back our original SBS with wonderful programs and with very limited advertising and at appropriate points if advertisements ensure funding.
There are far too many ad breaks which make te programs unpleasant to watch. Furthermore I am convinced these ads contribute to the obesity epidemy. Many people get up and to avoid watching them and take the opportunity to get something to eat.These ad breaks should be consided a health hazzard and banned. Some countries have ONE longer ad break ONLY in the middle and at the end of the program. Why not consider that if there must be all these ads
I disagree with ads – period. But given the current government position on public broadcasting funding, they have to do something. As a result (I like to think…) is that the quality of programming on SBS is far better than it was before advertising.
To those that say its excessive, have you watched the commercial channels? Or even the ABC? Useless self-promotion. Ads for programs we are never likely to watch because the ones they promote are CRAP!
We NEED a feedback system that tells the relevant channel we have just switched off!
SBS is becoming a basketcase — really tragic because before commercialisation it was world class. I tolerated commercials for the first couple of years but as it’s become progressively commercialised, I’ve given up and I don’t watch SBS any more.
I can’t watch films on SBS. Ads interrupt the flow of a film. Ads should be banned altogether on SBS (a public broadcaster!) – especially in films
It is annoying watching a film for instance with the ad breaks. It is impossible to fast forward them
Our solution to the excessive ads on SBS is to mute them. It disgusts us that a once-credible SBS has lowered its standards so much that it accepts money for promoting gambling.
We watch On Demand more than the usual programs.
I hate ads. I have to record shows I want to watch so I can fast forward through the ads.
SO MANY INTERESTING PROGRAMMES COMPROMISED BY INTERRUPTIONS
So many ads is a disincentive to watch SBS
We can’t stand the number of repetitive commercial ads that we are bombarded with on SBS, sometimes the same add is even played twice during that break. Now we record the programs we want to watch so that we can skip the boring, excessive adds which are intrusive and extremely irritating.
It is a political/commercial plot to reduce the value of the service so that reduced viewing numbers can be a justification for further funding cuts and/or sale to private interests so that they can *improve* it.
(Pardon the sarcasm, please.)
The same appllies, in principle to the ABC: reducing funding reduces content quality which in turn reduces viewing figures so justifying further cuts to funding etc.
Deliberate “Death by a thousand cuts” philosophy.
Far too many advertisements. Infuriating when same ads repeated over and over.
I mostly watch only the ABC or Netflix due to the excessive advertising on SBS.
There are too many intrusive ad breaks on SBS.
When ads were first run on SBS they came BETWEEN programs and never DURING programs…what happened to the initial promise that ads would not interrupt a program?
Too Adds and too repetitive one
As the government is apparently trying to get rid of the ABC and SBS the obvious course is to bombard people with ads. Even their new aim of putting more ‘typical’ Australians on the ABC is probably part of their drive to get rid of SBS by moving this content to the ABC. As the ABC does not allow right-wing propaganda to go unchallenged and presents a balanced view they are gradually disposing of the ABC’s more experienced and respected journalists and replacing them with
younger journalists who can be moulded into their image. We need an answer to this process to fight the gagging of the ABC and destruction of SBS by subjecting us to ads.
Too many adds and too many same adds on and on and on
SBS has gone to the dogs! I remember years ago when they went the way of adverts that they had to have high artistic content. As soon as they did the ‘Golden Handshake’ with McDonald’s it was straight down the vortex. I have given up watching anything on SBS after a continuous run in with their complaints dept. Watching On Demand through my Macbook Pro I experienced the same advertisement played sometimes 3 times in a row. It’s bad enough watching it once but 3 times? The complaints dept blamed my computer! How the hell can my computer choose what ads it streams? So to me SBS is history,the corporations through government are being successful in destroying both ABC and SBS.
We know that revenue is essential and the ads etc being run are against SBS’s charter. It’s time the Federal Government funded the channel and the ads could be less invasive. The only way we deal with it is by recording the programs we enjoy and then fast-forwad the ads.!!
The frequency and volume of ads has significantly affected the quality of SBS programming over the course of my life (now 31 years old, watched since childhood). Forcing revenue to be generated from ads has reduced SBS to almost the same level of distraction and hyperactivity as private-owned as revenue funded free-to-air channels, further reducing the incentive to continue watching. Wilful neglect by successive governments to undermine the quality is obvious. Only the saving grace of non-English language news and occasional good movies redeems it.
I do not watch the utter rubbish, ie reality shows and so-called lifestyle shows, telemarketing channels etc, so ABC and SBS have formed the basis of my television watching. SBS is now almost impossible to watch because of the ads. Like other viewers, I deplore any ads promoting gambling and they should be banned, like tobacco advertising. Please, please, bring back the old SBS. Because of the Covid restrictions I guess all of us are watching more TV than usual, and the excessive advertising is particularly noticeable.
I realise that advertising money helps subsidise the wonderful programming on SBS but exceeding the time/hour again and again is making SBS less appealing for viewers.
All these ads are ruining the viewing. Have an hour of ads at a designated time and people can watch or avoid.
Commercial advertising on SBS, as designed, disrupts viewers’ attention to program/film. For all SBS viewers who I know, it significantly diminishes their viewing pleasure, their learning and overall viewing experience.
The ads on SBS On Demand are so infuriating we have just about given up on it. If you need to ‘rewind’ a program, or go back to check a previous episode, or go back to where you were, you have to sit through the same ads at length all over again. Infuriating! There are some great programs available but On Demand is becoming almost unwatachable.
If you have to have so many ads, why don’t you do it like some european channels where they let you watch half an hour of a program,then have 10 minutes of ads? This gives people time to settle into a program without getting agitated every 5 minutes.
Robert H Birch put it exactly…. Please give us back our original SBS and leave the heavy advertising to the commercial channels, as was originally intended. SBS is an important part of Australia’s evolving culture, and the country would benefit from as many people as possible being exposed to its content. But with ads and promo breaks ruining the experience, the audience will only dwindle and opt for other content providers.
SBS is becoming unwatchable because of the constant interruption of programs, carried out with a total lack of sensitivity, often to promote their own programs ad nauseam (so presumably not even earning money from them). Very disappointing and anger inducing.
SBS ads are too often, repetitive, boring and for the most part of no interest whatsoever to me. They also do not cue well. Often a programme freezes after an ad, and then you have to start again, getting another rounds of ads as a punishment. Quite often, I simply give up and miss out on the excellent offerings that SBS has. While SBS could certainly do a better technical job, it’s not their fault that they need to put out so many ads to keep afloat. This sheets home to mean-spiritedness on the behalf of the people that refuse to provide sufficient funding for a service that tries hard to decently serve the public. Thank you.
SBS was right up there at the top of the television stations — not just in Australia, but in our world..and I have lived in the UK for the past 6 years so I know good television!!!
Please do not sacrifice the quality and the intercultural experience that you offer to the god of commercial greed! Give us back good television!
Ads and the frequency of them have ruined the SBS experience for me. I rarely watch it now. I hardly ever watch the commercial channels for the same reason, apart from the fact that their program content does not generally interest me.
SBS must obey the requirements of the SBS Act and the federal government should provide the funding it requires to do so.
I agree with the above comments. Watching a movie on SBS has become unbearable with so many ad breaks. What happened to the Charter of SBS? This reliance on commercial advertising should not be allowed.
Glad to be given the opportunity to comment. So sad our Government does not adequately fund SBS or the ABC.
Assuming that neither of the public broadcasters will be funded properly by this present government, I suggest that the ads they assume they have to have on SBS be kept to a minimum and not repeated. The same ad, be it for a programme or a product is stupidly repeated, often over and over on ad breaks. We are not idiots out here in Viewer-land! — Why not follow the European method of showing ads – by having them at the end of a programme and not interrupting the flow of what is being watched – often at the very worst time in he plot. Most of all I would love SBS to go back to it’s original format – without ads. I also have fears for the ABC with their continual and annoying promos for programmes – one feels that they are preparing us for commercials. I lived in Canada for 15 years and can assure my fellow viewers that the poor old CBC didn’t do any better with funds or programmes from having to show commercials. It was still hounded and kept short of funding – especially by the right.
SBS used to be a place of quiet uninterrupted piece where l could be entertained and educated. Now it’s like watching an awful commercial television station so l avoid it, which is wrong because l shouldn’t have to. Where else can you get such a diversity in culture? Stop the ads!
SBS as a public broadcaster should be completely government funded.
We need to return to public funding of our public broadcasters… accepting betting ads is a disgrace…We are turning off television more and more because of the advertising.
A single ad break per hour show, and some ads before it begins, would be a better solution. Often it is the same ads time and again including over multiple episodes, which I find self-defeating.
Whilst I too object to gambling ads they are everywhere including especially in our sports telecasts and sports arenas. SBS is a small part of a bigger problem in this regard
The streaming ads are hopeless. Many times they crash the ap and I have to restart and watch all the ads again. It detracts massively from the viewing experience.
SBS on demand seems just as bad and it also stalls sometimes trying to play adds which is super annoying as then when you reset you have to re-watch all adds again to get to where you were up to.
On SBS movies I sometimes feel like I am continually watching adds.
SBS was once an enjoyable experience much of the time. One could watch a quality movie meditatively and with concentration. That is no longer so. A great disappointment.
I just don’t watch SBS anymore. It isn’t any better than commercial tv.
I particularly dislike SBS on-demand – same ad bashing format and I also dislike having to ‘log-in’ and give my email address etc. so I don’t.
It was an absolutely wonderful TV format before the Liberal government began bashing it and the ABC.
Bring back the old SBS
Too many ads. I used to only watch ABC and SBS partly because of the fact that I wouldn’t be bombarded with ads. Sadly this is no longer the case. SBS often replays the same ad twice in one break. Often it’s the same one over and over during a program.
SBS should be ad free.
I am completely fed up with the commercialisation of SBS.
This a consequence of years of coalition governments and their constant attack on public broadcasting.
SBS is a poor copy of the commercial channels
When SBS went commercial one of the main selling points of this tragic betrayal by government was that there would be no advertisements during programs. Surprise surprise look how Neo-Liberal commercialisation has once again wrought destruction.
Far too many ads. These have changed SBS for the worse
We too have decided to watch less on SBS because of the constant advertising, especially because some of those are questionable,
Becoming far too difficult to watch, even on SBS on Demand.
There are far too many ads on SBS, which I find very annoying. I watch shows on SBS On Demand and it is very frustrating to have so many ad breaks and not natural breaks in the program. I now only watch those programs that I absolutely do not want to miss!
The ads frequently break into a program or movie at a crucial time in the story-line. More appropriate placement would reduce the irritation.
I think those running SBS – especially the marketers – are wanting to prove their worth to work in privately owned commercial TV. For its sins, at least privately owned commercial TV is answerable to their shareholders.
With SBS those running the station are not answerable to their ‘shareholders’ – the Australian public.
What the figures show is that a key reason for all the commercial breaks is for an excuse to run all the station identification and promos. The SBS marketers act as if they think SBS viewers just have the TV on all the time in the background – and thus constant repetition is needed to get a message across. The constant repetition is not just showing a promo once per program, but very often many times during the one show.
I could go on, but I’ve vented enough.
Unethical gambling ads result in destruction of families and promote the idea that gambling is acceptable in Australian culture.It is not. Disruption to programmes with heavy commercial advertising has forced many of us back to ad free ABC viewing. The incursion of this deluge of ads spoils the viewing experience and is lamented by many.
There are far too many disruptive ads on SBS in prime time viewing. Please remove or at least lessen that number. Thank you
Far too many ads, to extent of watching SBS annoying.
Poor interpretation of multicultural charter with too little program material from non Anglo sources.
The ad breaks are excessive. If we have to have breaks in order for the SBS to operate financially then please group them together at the beginning or end of a programme. I recall when living in Italy for a time that one of the TV stations did that. The ads were in fact quite entertaining and clever at times and people would still watch them for that reason – but the flow of the programs were not disrupted.
The worst timeslot for ads seems to be the US ABC News at 12.30 to 1.00pm. In the final 10 minutes of the show there can be a 10 second news segment with 1 or 2 minutes of ads. It is absurd and insulting to the intelligence.
The same ads are on over and over, especially irritating insurance ads. There are also far too many repetitive promos.
Even the movies are interrupted!!!!
Please!
Too many ads in a row during many programs and especially dreadful betting advertisements that are on quite early in the evening. There must be an alternative to these gambling advertisements.
SBS is our primary tv for news and entertainment. Our ethics do not agree with commercial overload or gratuitous private publicity. Bring support our quality programming without bombarding with unwanted, puncturing extras.
I don’t mind some advertising per se but prefer that we don’t have any gambling advertising, no repetition per advert break, and not the ads as seen on most commercial channels. Best for longer ad breaks at the end of programmes and less disruptive, shorter ones during a programme.
I personally think we should be lobbying the government to return funding to ABC and SBS as well as supporting the local content makers rather than stripping money from these locations to fund rail lines for coal mines that wont return any revenue to the government anyway. I support SBS using advertising to make up the short fall in their budget due to this de-fund from the government.
Definitely loose the gambling ads. Im ok with SBS promos, in fact look forward to them. But generally speaking, ads break/spoil the flow of the show, are irrelevant to me, and just annoying. If you have to have some ads, put them all up front, or at the end.
I have always opposed commercial advertising on public television broadcasters. I was shocked when lit was introduced on SBS. At the time it was mooted that the federal government wanted to introduce commercial advertising on the ABC, but, thought there would be such a strong opposition that they restricted it just to SBS. I am one of many people who regard advertising as propaganda – a form of brainwashing – and reduce my exposure to it whenever possible.
Oh Dear!
Please do what ever you can to stop the scourge on our mental health with all these ads that buy into our worst neuroses. The programs we want to watch being continually interrupted with emotionally manipulative attacks on our minds! So little regard for the human effects of such continual attention disruption and bad habits…
It’s hard to watch SBS these days and evenings due to the constant interruptions by repetitive advertising and promotional material being plonked into good informative shows.
This is a rich country, we can afford to have a national broadcaster funded from taxation. I am happy to pay tax for this. Not so happy to subsidise coal mines.
I agree. Ads with no sensitivity to program content spoil any film or program.
Gambling is a scourge of the community. Promoting it should be banned.
As a public broadcaster SBS should not have to run so many ads. SBS should be funded by tax payers through the government. The number of ads tells us as viewers that SBS is intentionall underfunded by the present government and this needs to change. When SBS viewers see the ads they understand what is happening and are unlikely to buy or be persuaded by the ads. This makes the whole process counter productive. Hello – fund SBS to enable this valuable service to reach all our communities.
I would prefer not too see ads on SBS, particularly those that encourage gambling but I tolerate them because of SBS’s quality programming.
I agree with those who oppose gambling ads. We have a problem with gambling in this country and we should not encourage it with advertising. No more gambling ads, please.
We need SBS to be appropriately funded as it initially was formed. This starving of funds indicates exactly what sort of Government we have.
Not only is SBS at the point of becoming unwatchable because of the number of general Ads, what is even worse is that they are now bombarding us with gambling Ads that are a cancer on the social fabric of our country. I fully understand that SBS needs Ads to exist these days (due to decades of funding cuts by governments that have transformed SBS into just another commercial channel instead of the vibrant multicultural channel it once was.) But I’m appalled to see that SBS has accepted its ‘commercial’ fate and is stooping so low that gamblings Ads are now a regular nightly part of SBS viewing. Where do they draw the line on Ads that are socially acceptable? Has Management, and the Board, no moral compass any more?
Todays constant bombardment of commercials destroy the pleasure of watching a program! It has lead me to recorded every program I like to watch, so I can fast forward through the add’s, I am totally wearing out my remote control!
Is there any way that the advertising could be relegated to between programs – especially where the program is of 30 minutes duration? Maybe in longer programs, inserting the advertising into a natural break in the story? Nothing destroys the tension in a program that has some, than breaking it with an ad for a bloody bank or promotion.
Doesn’t SBS have any say on who can advertise? How about seeking this revenue stream from companies that are here to improve our world rather than exploit it (I’m looking at you, gambling companies); those businesses that align themselves with an improved world.
BUT in a perfect world, SBS would be publicly funded.
And keep up the good work with your news service. We want reportage; not editorialising.
The ads are unprofessionally spliced into program content. They immediately cut-in with no buffer of black screen. The unprofessional way in which they are spliced creates an immediate psychological jar and typically imposes an abrupt emotional severing from the program being viewed. The cut-in frequently overlaps with a scene break and so another scene continues for a few seconds when the ad breaks in.
It is the worst example of ad integration of any screen media organisation. Abrupt and jarring.
I wholeheartedly agree with the sentiments expressed by many of the above, to wit:
FAR too many blatant adverts and “promos” that are really more adverts; and
WHY do we allow so many (any?) gambling ads- they make it look as though gambling is a natural/macho thing to do when really, for many people, it is an addiction that causes so much family distress and financial hardship. If people MUST gamble, let them have to go and look for it, not have it rammed down one’s throat all the time!
Government funding is to blame for the sad state of both SBS and the ABC. Both organizations do a fantastic job, but I doubt if Liberal or Labour will right this terrible wrong, so I don’t know what the answer is; what I do know is I quite often switch over to the ABC when an a long group of SBS Ads ruin what I am watching.
We only ever watch ABC and SBS but there’s less and less SBS in the mix – the ads on streaming are particularly frustrating. And the addition of gambling ads is amoral and immoral, it is a huge problem in this country – how do they get away with advertising this?! Public broadcasting without commercials is essential.
Mostly watch SBS on demand. The more recent the program the more likely that they will ramp up ads closer to the end of the show.
The advertising was forced by SBS.
I’m a deleter too. We are legion!
It is becoming as unwatchable as the so called commercial stations. The continuity of the programs is often disrupted by an ad break that goes on and on and on to the point the program becomes impossible to watch. There is less creativity and community input it seems. A great shame it is going as bland as the others so I only watch ABC if I watch anything now.
Australia,should be proud of SBS and the services it provides.The current Federal Government has done a great disservice to the nation by cutting funding to SBS,something that Tony Abbott promised not to do.Yet they can spend $30million to fly an innocent well respected Tamil family to Christmas Island.
Not only are there too many ads but the placement is intrusive and crude. There have been times when they have occurred mid-sentence which is really annoying. it may have something to do with the fact that much of their material is from programs which have no designated ad breaks eg. BBC. public broadcasting.
The above comments highlight the fact that ads irritate the SBS viewers and so would have a negative effect on the advertisers. SBS is a national responsibility and resource so should be funded, nationally – through taxes.
Get rid of the gambling and junk food ads, then start on the crass, brainless, drivel that aims to prey on our insecurity and envy. If ads aren’t engaging and amusing, they should be banned as audio, visual pollution. And ban the bleating, sanctimonious, hypocritical politicians as well.
The original intention of SBS was to be a ”multicultural” station. Now it is a ”multicorporate-multinationals station”.
Big money wins again, coupled with, of course, politics to the right of the spectrum.
Plus government funding shortfalls to all people-centred organisations. Look at the ABC, struggling, the arts organisations, struggling, but big Hollywood movies that are filmed in Australia are given millions.
Australia is becoming such a sad country where it denies the larger populace in favour of the multinational companies.
The increasing number of dubious advertisements on SBS such as gambling advertising is totally inappropriate but also the positioning of advertising during programs is not only annoying but it disrupts the flow of any program. SBS and ABC are the only channels worth watching but the intrusion of more and more ads on SBS is beginning to grate.
Is SBS ever going to stop demonising white australia and slavishly following the big end of town’s demand for a never ending supply of customers with the obviously devastating environmental qonsequences?
If it weren’t for SBS & ABC we wouldn’t watch TV! We totally love the content but the ads are ruining the experience especially now they are competing with ad free streaming services…
More government funding & less ads – tax the miners and less handouts to private schools!
If we must have ads to pay for content OK, but cut the promos out-and no more gambling ads.
Ad breaks seem to be longer and longer.
And LOUDER AND LOUDER
It is ironic these three questions. Last night I made the comment that the number of ads was getting to an excessive level and bemoaned the time when SBS was ad free.
It’s very frustrating trying to keep track of the Tour de France with all those interruptions which are very repetitive and annoying! Why promoting own programs so often? It’s nice to know those programs are coming up but your viewer isn’t a goldfish and will remember the day and time…!
Definitely too many ad breaks and getting worse all the time
SBS is not a commercial station. I do understand the need for revenue raising, but let’s leave the service in the category of tax payer sponsored community world news services
Excellent that Save Our SBS is doing this survey so we can plead with SBS to leave the ads to the commecial channels.
Like our wonderful ABC, which is constantly under attack from often biased commercial interests, SBS is a precious community asset. It should be properly funded, without being beholden to advertising revenue to carry out its critical role in our diverse society.
SBS and SBS On Demand have become virtually unwatchable. The high frequency of ads destroys continuity, and the repetition of ads in the same ad break on SBS On Demand is also infuriating. I always put the TV on mute when the ads come on, and I assume many others do the same. For goodness’ sake stop ads during programs!
Thank you for this survey about SBS. The ad breaks have certainly increased to disproportionate levels and this is not acceptable. Also, watching SBS on demand, the interruptions with advertisements destroys any continuity with the storyline, whether it be a “movie” or “serial”. It is so frustrating and I must admit I’ve given up on so many occasions and turned off. I know in my instance you can’t fast forwarda through the ads either. Has the increase in advertising coincided with Covid, as it was never as bad as this.
We need SBS to be returned to what was originally intended, the same as the ABC with no advertisements, certainly leave all advertising to the commercial channels.
Too many ad breaks, and often in contrived places. The thread of the program is lost. And please get rid of gambling ads. There are far too many of them. Even one is one too many.
I love SBS and realise you’re forced to do this for revenue – shame on government who are continually eroding public broadcasting.
My son said just last night, when I asked him to turn to SBS, I never watch SBS anymore. Too many ads!! And he’s a commercial tv viewer!! That is saying something. I also find the promo extremely annoying. It has got to the stage where I can’t bear to watch the programmed they’ve been endlessly promoting when it comes on. Truely the promos ar3 over the top.
SBS is becoming as annoying as the commercial stations with huge increases in the number and types of of ads and lengthy interruptions to shows. Five minutes of SBS promos, products & services offered, and community announcements halfway through shows of longer duration, or between shows is acceptable.
My husband and I have enjoyed watching SBS over the years but our viewing time has diminished because our enjoyment is lost with the constant irrelevant ads and disruption especially to movies and documentaries.
Please give us back our original SBS and leave the heavy advertising to the commercial channels, as was originally intended.
SBS regularly breaks its own code of conduct. Ad breaks are supposed to only occur between programs and in natural breaks in the shows. Quite often there is no break between one show and the next, with all the ads and promos being placed within the show. And the promos are just as annoying and overdone as the ads. This is just treating the viewers with utter disdain. SBS as it stands is a complete failure, with none of the distinctive characteristics it had when it started.
Most in-program commercial breaks on SBS look not just annoying, but noisy, over the top optimistic therefor artificial and have no imaginable connection with “the host” program. They steal from us – our time, attention and put us in frastration mode.
Apart from the ads, I also like to read credits on all programs. Please don’t minimise credits in favour of promos for other programs.
SBS is dumbing itself down with advertisments that don’t suit it’s role as a progressive channel for progressive people. There are enough fodder channels already.
SBS now looks no different to any commercial channel. Let’s restore SBS
to its original charter. At the very least, reduce the number of ads and move them the program breaks
I’m watching SBS less these days because of the ads. SPending more time on Youtube where I have a paid subsrciption and no ads.
I am also disappointed with the amount of gambling ads. I always switch the channel as soon as they come on, which then takes me to another channel & program. Also what I find really annoying is, the ad playing then played again, I get the information the first time and really do not need it forced on me again This also makes me change the channel.
This is a magnificent service unique to Australia. Let’s celebrate it, not reduce it to the same level as the rest of commercial TV.
Rarely watch now, can’t stand the rubbish interruptions. ABC only one left, and it’s heading the same way with infuriating repetitive self-promotion ads. At least they’re so far only between programmes. Have become expert at using the time shift function to allow skip through ads and promos at speed without sound.
All ads that affect lives in a negative way should be removed, ie health, gambling, self-image. They should be no longer than 15 secs & in blocks between programs so that we can concentrate on the program the maker intended, not what the advertiser intends us to see. Sometimes an ad begins in the middle of a dialogue for goodness sake! Contrived is too kind a word, it’s a disgrace, a slap in the face to the viewer & the maker.
Lose your ads or lose your viewers!
These ads are in contravention of the agreement. The breaks often go across important scenes spoiling dramatic effects.
The attractiveness of SBS is ruined by the ads.
My favourite News program…..I love world movies
There are far too many ads on SBS. At most, there could be a few relevant in-house promos and a few important govt announcements – at non-disruptive points in the programming.
The funding of SBS should ensure that ads are NOT required.
I’m becoming convinced that it’s all part of a great conspiracy to soften our brains so that we can’t think at all, by training us not to be able to concentrate on anything serious or important. If the SBS act allows this sort of thing it should be changed and the people responsible. should be held accountable,
Too many too long too annoying & inappropriate.
SBS, lose your ads or lose your viewers.
I don’t have much time to watch TV but I watch SBS-ondemand and it is easily noticeable the increasing number of adverts which has become really annoying.
We can’t watch commercial TV because it is so ‘dumbed down’. ABC and SBS are being eroded in the same manner, which is making us watch Pay TV. This is iniquitous and is against the spirit of Australian fair play, because it discriminates against those who can’t pay. Television is the best educative media invented, yet capitalism has corrupted it and turned it into a trashy nightmare. ABC and SBS need to be funded by the government with no interference from capitalist corruption. They should be a resource for the Australian people, not descended down to the level of commercial television. Australia needs an independent system to raise the standard. At the moment we are faced to turning the set off. What a shame !
John Howard’s ‘requirement’ for advertising, as funding was withdrawn, is a strategy for privatisation. Now we have repetitious ads and meaningless promos that discourage program viewing, undermining the purpose of SBS to address the social complexity of Australia and promote social cohesion. The use of these randomly placed repetitive interruptions to programs broadcast and particularly when streamed just pisses people off. And attacks the idea of a public broadcasting service. There is continual pressure for the ABC to be similarly undermined in its public role.
Advertising is just as bad on On Demand. I have had ads over-ride the mute button on the site. I would rather pay for content in On Demand than be exposed to irrelevant, obnoxious, infantile advertising.
Objection to the plethora of ads – alcohol and gambling ads are anathema. Let the advertisers do their stuff on private/ pay media
Tax payer funded media should be balanced and essentially aimed towards
information and entertainment which is not socially destructive.
I agree, far too many Ad’s but with this government hell-bent on slashing funds to SBS (and ABC),they have to get revenue from somewhere in order to continue broadcasting!!!
Three cheers for the ABC’s commercial free TV – Promo ads only BETWEEN programs.
SBS…..?????????
I have been shocked by the amount of advertising currently displayed on SBS. It interrupts the flow of shows and is unnecessary. I watch SBS & ABC to avoid advertising not get more than commercial channels. Bring back the integrity of SBS Government funding. Murdoch owns enough media leave our public stations alone.
Please remove all gambling, sports bet ads
I can’t handle the huge amount of interruptions now when watching a programme on SBS, I don’t watch the commercial channels because of the advertising.
I am forced to now only watch ABC, which I love , but would love to have the choice of programs on SBS
I think that SBS should be totally commercial free and there should only be public service messages between programmes only and that SBS like the ABC should be sufficiently well funded to do its job properly ie be a true ‘Vox Populi’.Maybe some sort of broadcasting licence should be reintroduced or a thumping great levy on commercial media, including all radio and television advertising. Make the reprehensible reptile and porky packer pay.
I find the ads disruptive to the enjoyment of a program, but appreciate SBS needs the income. I don’t think the program directors have a good grasp of how and when to insert an ad though, how often is acceptable and not just self defeating, how repeating the same ad over an over is counter productive to the advertised product. And, I agree with all the comments against gambling ads – SBS needs to draw a firm line on this, and executives will just have to suck up to the potential loss of bonuses.
I entirely agree with Bob Y (1.9.2020)
The Federal Government is doing everything possible to destroy SBS. It is about time that our taxes are used to support the SBS.
I don’t watch many programs on SBS/SBS on Demand because of the number of ads interrupting their continuity. When watching a movie or series, the ads usually come on at crucial moments in the story, which is most annoying. All gambling ads must be removed as they only encourage addiction and promote an unhealthy life style. Also, showing the same ad twice in one break is like telling the viewers they are not capable of understanding it the first time, an insult to people’s intelligence.
I agree with too many ads, but here’s a tip: if the same program is on NITV watch it there! No as many ads l have ! Gees l wonder why!
thanks for trying to do something about it
We love all things SBS, but we are finding that we are turning of the TV to go to bed and read. The number of ads and promos is just rediculous. We never watch commercial TV, because off The ads and generally don’t have the sort of show we enjoy.
Frequent ads and repetitive so one is put off rather than wanting to watch, buy or whatever.
The excessive and repetitive ads are useless or detrimental to advertisers, as they are overdone multiple times within the one hour, and thereby make viewers annoyed at the products intruding on their programs.
These interruptions are a serious impost on our viewing experience, degrading significantly the involvement in the program, due to tension being broken and continuity of story lost.
I would prefer to have lots less adds on SBS
What’s the use of having a public broadcaster if it is only full of shit ads?
It is really off-putting to have the breaks. They are badly timed too, and it put me off watching anything on SBS. So disappointing.
Rather than advertising rubbish, why can’t the government better use the resources of SBS to promote social goods and desirable outcomes that is supposed to be striving for through its other various policy measures? The savings that can be achieved make it a worthwhile business case. Instead, SBS is used to promote for-profit and arguably, destructive outcomes like gambling. It’s crazy.
Gambling adverts are the worst and SBS should avoid these adverts at any cost considering the social damage caused by current levels of gambling without encouraging even more. Other advertising is disruptive to quality programs and put me off watching SBS that was once my preferred channel.
Free to air TV is a beaut resource. We used to watch just SBS and ABC programs due to the generally more interesting content. Now we mainly watch the ABC because of the number of, and frequency of, disruptive ads on SBS.
We put the ads on mute. This gives us some degree of control over a very annoying and frustrating series of ads. Many are repeated over and over again
Agree with all the above
As an 84 yo pensioner (educated). I watch ABC, SBS and NITV exclusively.Commercial TV is a wasteland. I will not be dumbed down by the acolytes. SBS should wise up and reduce the number of ads and promos they are unnecessary.
Have noticed the ads on this years Tour De France esp the highlights package and on the streaming service…very distracting and disruptive. And if you are trying to return to where you left a show off on the streaming, you are forced to watch the same ads over again….And No to gambling ads.
I love the SBS and would love it more without ads. The programs that are on SBS need to be screened fully without any breaks at all
My wife and I watch SBS on demand exclusively, as it allows us to choose what and when we view.
The breaks appear quite randomly inserted into the programmes, which can be irritating and very repetitive. Some marketing guru may expect to eventually grind me into submission or I could more than likely be turned off. I think SBS on demand is less prone to advertising interruption?
SBS appears to have too many adds promoting their own shows when adds for paying advertisers are already too much. There’s also severe repetition of adds that are played in EVERY add break, often TWICE from one company or another who have obviously bought a package. The programming also seems to have a bias with constant shows about the Royal family, British railways, buildings and other successes of the mother country while reminding us of the horrors of the holocoust and the Nazis.
It’s quite clear that viewers are unhappy with the current situation. It is time to return to the founding philosophy. The many benefits provided to the community by Public broadcasting means they need to be FULLY funded by all taxpayers, ie the government. Advertising has no place on public broadcasting and is best left to the privately owned commercial entities.
What a turn off these SBS ads are. Totally unrelated to the foreign, foreign language and indigenous programs that SBS is based on. Ads just cut through such a principled position.
Too many ads
The ads are really disruptive. I may as well switch to Netflix!
ads are not consistent with public broadcasting
I record SBS programmes and fast forward ads and promos.
It seems utterly absurd to break a programme, especially on World Movies (Ch 32), for a self promo. That’s just crazy!
And the number and constant repetition with each new break of promos is mind numbing. There are programmes I’ve been so sick of seeing advertised ad nauseam I can’t bring myself to watch them!
STOP IT!
My Mute button is worn thin.
there is way over too much advertising and promos. eg the War of the Worlds just cuts in at an inappropriate time with advertising. Same with other prime time programs such as letters and numbers, TDF, news bulletins etc.
please stop ruining the enjoyment of sbs shows and programing with excessive advertising and promotions.
I can understand why sbs needs to raise revenue by commercial ads.
But I do not understand why it needs to air constant promos for its own programs in the middle of its broadcasts.
The constant adds about Australian children in poverty are insulting, depressing and pointless. And did I mention constant? They forget that in some homes, little children are watching and the adds contain miserable concepts and suggestions. When I raised my children in poverty, I would NEVER have gone anywhere near The Smith Family with their TV adds adding to the stigma.
DO NOT TURN SBS INTO A COMMERCIAL STATION, WE HAVE ENOUGH OF THEM ALREADY. WE WANT OUR ORIGINAL SBS SO STOP MESSING WITH IT!
I agree with most of the above comments.Whilst we appreciate that funding generated from ads is of
great importance to the successful running of the channel,I believe that your ad breaks are too
frequent,untimely,repetitive and hugely disruptive to the flow of programmes.
I used to love SBS but it is now unwatchable due to ads during the shows.
I am totally against gambling ads. Problem gambling is huge and particularly rife among poorer vulnerable people. It’s a cause of domestic violence and childhood poverty and neglect. It’s as bad as cigarette advertising and should be banned.
SBS has been loved and valued since its inception. All ads are disruptive and detract from the viewer’s experience. In particular, the gambling ads should be completely removed from SBS because they promote a behaviour that is detrimental to our community. However, if funding from advertising is unavoidable due to the current Federal Government’s decimation of public broadcaster funding, then the placement and timing of ads should be done in the least disruptive way possible.
Please remove gambling ads from SBS. Public Broadcasting should not be used to promote this activity which creates such misery in the community.
Advertising undermines democracy by corrupting the free press.
By its very nature advertising is indoctrination.
Not only does commercial media distort the news to reflect the interests of those with money and power, but it uses the most creative minds to manipulate our very thought processes.
I say NO to advertising anywhere, but particularly in our public media space.
The ad breaks are very irritating an d do seem to just appear without any respect to the program showing.
We watch SBS a lot and it is becoming a problem .. SBS was a refuge from high Ad content, but is much less so, now.
It is an absolute disgrace that SBS an allegedly national, public broadcaster, is prepared to DISRUPT and DISSIPATE its own programmes just to tell the audience about its other programmes, gambling, fast food, junk food, fast cars, junk products for landfill. IN extremely loud, raucous voices.
Now occasionally SBS DOES offer something worth watching, although MOSTLY its programmes are on their 5th repeat or feature gratuitous violence AND it is hardly worth while anyway because of the disruptions and cacophany.
Today’s SBS defeats its own entire raison d’etre which WAS to provide an alternative view, one centred on multiculturalism, liberalism and equity. All it is now, is a version of the nasty commercial networks only concerned with the worst excesses of capitalism, appealing to the national pastime of longing for whitegoods and interrupted every few minutes.
THERE ARE FAR TOO MANY ADS ON SBS AND TOO LITLE VARIETY IN THOSE ADS, TO THE POINT WHERE THEY LOSE ANY OF THEIR INTENDED IMPACT. SATURATION ADVERTISING OF THE SAME MINDLESS MESSAGE DEFEATS THE PURPOSE OF ADVERTISING.
FAR BETTER TO HAVE A FEW, WELL THOUGHT OUT AND WELL SPACED ADS WITH AN IMPACTFUL MESSAGE THAT SPEAKS TO THE SBS AUDIENCE.
ORIGINALLY IT WAS 3 ADS AT THE START AND CONCLUSION OF A PROGRAMME – NOT THE CONSTANT INTERRUPTING DRIVEL WE ARE NOW SERVED UP.
AND THE SAME APPLIES TO SBS ON DEMAND
LETS GET BACK TO THE ORIGINAL CONCEPT
Whilst I am of the opinion there are too many commercials on SBS, I enjoy seeing the advertisements for other programs and I have actually become interested in and watched other programs as a result of seeing the these advertisements.
It’s dismally sad hearing Mike Tomalaris talking about dual-turbocharged Skoda engines in the middle of a Tour de France broadcast.
It is worth appreciating, and adding to the tally, the implicit advertising in every description of a racing team by its sponsor’s name and every mention of SBS’ “partners” in the broadcast. That alone would be tolerable, if irritating, but that is on top of the excess of explicit advertisements.
Both the ABC and SBS need to be fully funded back to 2010 standards
How can a largely taxpayer funded broadcaster justify so many ads? It is a great pity that many people are becoming disenchanted with SBS as their programs are varied and interesting.
The gambling ads especially are destructive and socially irresponsible.
Like many others I record programs on commercial stations the delete the ads when watching the recorded items. It is still inconvenient but much better than suffering all those commercial fantasies.
It has become a huge disincentive to watching SBS at all.
Perhaps if the Federal government had not drastically cut funding to SBS there would not be that many advertisements on the channel. Don’t blame SBS for tryin* to raise revenue. Protest to the Federal government
Please reduce the number of ads and eliminate the gambling ads. The ads are a real disincentive to viewing.
SBS used to be a pleasure to watch but it is increasingly spoiled by the huge number of ad breaks. Moreover, the ads promoting SBS are unnecessary and SBS should not accept advertising from gambling interests.
SBS is a wonderful tv programmer it’s a shame there is too many ads in particular the gambling ones
There are some excellent programs on SBS but they are spoiled by the frequency of the nauziating ads and promotions.
I used to work as a program controller (switcher) at TVW7 in the 1970s and 80s. I find SBS so infuriating now that I record anything I want to see, then watch it later,
using the skip button to bypass all the ad breaks. For pity’s sake, always two promos going into all breaks, anything up to five commercials, then three promos coming out.
And so repetitive! I can’t stand it. It’s far worse than the commercial channels. I can hardly watch SBS these days.
SBS has always been my favourite free to air program for its diversity and amazing content. It is very disconcerting as time goes by, the ‘ad’ content is becoming more prominent. It’s a sad indictment that such a wonderful service is being consumed with advertising material that breaks the momentum of all programs available. I sincerely hope something can change this otherwise perfect media platform.
As well as too many ads and promos I also take issue with the tone of many of the latter. So many programs on SBS and SBS on Demand are violent. I hate been forced to watch these violent promos and have really minimised the time I spend on SBS as a result.
One thing I will give them, is at least they don’t promote fatuous comedy programs over and over like the ABC do. LOL
I hate ads. I have to watch commercial channels for sport but otherwise I cannot stand ads.
Not only are there too many ads, but they are then repeated over and over again throughout the night. I would watch more on SBS if it had fewer ads.
Excessive advertising is precisely why I don’t watch the commercial channels, or at least I record them so I can then fast forward! It’s the advertisers’ loss… Please, SBS don’t go that way!!
Even watching SBS on Demand is a trial these days, due to the amount of ad and promo breaks, and the app itself is dodgy a lot of the time too — sometimes the program refuses to load again after the breaks and I have to quit the app and go back in. All in all, not an enjoyable and seamless experience, which is what streaming should be.
The government should fund SBS adequately so that it does not have to rely on advertising for revenue. Advertising can compromise the integrity and independance of SBS programing.
I cannot abide ANY advertising, so I only record programs and fast forward through the ads, if I really want to see something. But mostly just watch ABC now for all the above reasons. A Shame that our government in their “wisdom” has chosen to devalue our public broadcasters.
Advertising should be limited to a short period between programmes and not disrupt the flow of a programme.
I used to love watching SBS and SBS Streaming…..now it’s almost like watching a commercial channel…..and yes, the “ad” breaks are really disjointed and can come in the middle of a conversation. Incredibly annoying
My brother was a compulsive gambler. It destroyed his family and eventually contributed to the shortening of his life. The extent and range of gambling advertisements on television and in sport, including those aired on SBS is appalling. I realize that our governments have become dependent on the taxation income they receive from this iniquitous source, but it does no service to the Australian population to make SBS partially dependent on income from airing gambling advertisements. Gambling is equally as abhorrent with smoking, and alcohol and illicit drug use and abuse. Greatly improved ethics in the type of advertisements allowed on SBS is highly desirable.
The sneaky practice of shortening the interval between ads leads me to the conclusion that viewers are being treated as brain dead. My action is to turn off straight away.
Let the commercial TV channels have the ads. We don’t need to watch them on SBS. Culture and adverts do not go together. Ban the ads and reduce the promos.
I only ever watch SBS 1 as I cannot stand the programs on Viceland nor am I interested in movies. It is a shame really I used to watch SBS 2 and ABC 2 but since their evisceration Both TV stations have become unwatchable to both my wife and myself.
I find that SbS has some great informative shows and a lot of very interesting subjects. I do however deplore the amount of shows relating to the queer set.
I used to enjoy and value watching sbs for the excellent content. Now it’s almost unbearable with the same heavy advertising as the commercial channels. This is not public broadcasting.
Gambling ads are an abomination especially during sports broadcasts.
Almost seems like a deliberate self- destruct of SBS. Definitely noticeable and detrimental to viewing.
community service announcements only please.
Please let us return to the good old days at Our SBS, it is a public broadcaster not a commercial one.
At the moment programs are disrupted and spoiled. They may even be avoided because of this, or else taped – but this is also disruptive. Gambling adds, repeated adds, etc, I find this offensive! Our multicultural society deserves better.
The only good thing about the ads is that I’m able to take a ‘Nature Break’ whilst watching Le Tour de France. The gambling ads are the worst; absolutely unsuitable.
I’ve stopped watching SBS because of the intrusive advertising.
I exclusively watch ABC & SBS. SBS has been eroded over time by too many advertisements. Should be no more than 3 and only every 30 minutes. No Gambling or Betting advertisements. Stop repetitive insurance and banking advertisements.
Thank you SBS for your fantastic shows…
Our SBS is being ruined by so many promos. It has got worse over the years. If our National Government knows the importance of an informed public they will be fully aware of the decline of our national sister programme so why is this happening at this crucial time.
Definitely too many ads and promos particularly gambling ads which are just appalling.
In the current environment of political hostility to publicly funded broadcasting, the constant cuts, attempts to muzzle and the rising costs of quality content, it would be outrageoulsy stupid for supporters of the network to add to the funding disruption. It is hard enough to attract advertising – note the struggles of commercial broadcasters to turn a profit – to attack SBS funding this way is actively prosecuting the NeoLiberal agenda for the extreme right.
I find the notion that mere “viewer pleasure” should caused detriment to the enhanced independence SBS enjoys a selfish stupid, short sighted and self defeating proposition. Why are you so focused on sabotaging the station, the quality of programs able to be made and purchased, and its political independence? Are you the neoliberal fascists in grumpy pants clothing? Please think again before you proceed with this foolishness.
Being required to accept commercial advertising to partially fund itself, the SBS, unsurprisingly, exposes itself to conflict of interest pressures, rampant throughout commercial mainstream media, and, inevitably, this will be reflected in the SBS’s degree of exposés and investigative programming. It is not easy to bite the hand that feeds you, and almost always results in less food coming your way.
As if we need more low-grade television than we already have!
to many Ads on sbs,they drive me crazy.sholud be a limit of 2 to 3 only.
I understood that originally SBS WAS TO BE ALMOST FREE IF ADVERTISEMENTS, BUT OF LATE IT is becoming almost as intolerable as the commercial channels, particularly so in the middle of films and serious documentaries.
Too many ads. Do not want to see SBS content influenced by commercial interests
My husband & I are also very annoyed at the number of ad breaks that go on & on!
They are repetitive, & take up a lot of time, & sometimes they just cut into a program with the break indefensible in the context of what’s happening in the program.
SBS is now as bad as the commercial channels!!
SBS used to be our favourite station but not any more. The number of ads and the frequency with which each ad is repeated has made both SBS and SBS OnDemand unbearably irritating. Great programming has been made unwatchable. Please stop!
The amount of ads now can lead to a turn-off, literally, from what are many excellent programmes. Often they break in at completely inappropriate times, almost in the middle of a sentence. Definitely should b e more funding for what is supposed to be a public broadcaster.
Frequency of ads is very disrupting and tends to put one off watching foreign films and serious documentaries. Jennie Brockley’s programme’s on very sensitive issues is ruined by disruptions.
How can gambling ads still be legal? Does SBS not know the overwhelming evidence that legal gambling is amongst the most destructive forces in our society?
And the endless NSW Police mob ads that remind us that 16,500 cops roam our roads to fine us for large and small infringements. So depressing to have seen this same ad about 10 times last night during ‘Get On Up’ film on SBS!
I know I live in a police state; these ads are not helpful!
Nowadays there is very little to distinguish SBS from the commercial stations, which I refuse to watch. Apart from a handful of core programs, I can’t bring myself to watch SBS live to air
The commercial advertising on SBS is excessive and ruins my enjoyment of the programmes. I do not watch ads and so will record in order to avoid having to watch them. I find gambling ads and their association with sport, particularly distasteful. It is such a shame that SBS has resorted to this approach, which has lowered the once wonderful standard we had come to value and appreciate.
I only watch streamed SBS nowadays; there are far fewer ads or promos than SBS live (although they’re unavoidable – but they can be muted).
we need the original sbs back as it was when it first began
SBS has enjoyable content, and ads don’t ADD to any program. SBS is getting no better than every other channel. Too many ads that break the story line. At times I can’t be bothered and change the channel, where I find more ads. Whats next, a program of ads with a sprinkling of content.
I agree that there are too many ads on SBS. I would particularly like to see gambling ads removed.
Our family watch SBS almost every night. The amount of ads have increased and are very disruptive to viewing. The promos are excessive and (almost) put us off watching the upcoming program.
Advertisements and promotional material should be restricted to between programs, as when advertising was first introduced.
The number of ads in a row is ridiculous. We used to watch just SBS and ABC. Now it’s pretty much just ABC because of the number of, and frequency of, ads.
Sad, because SBS has excellent programmes but the advertising is badly timed and changes everything.
If I wanted to watch a gamut of advertisements, I would tune into a commercial station. As I deliberately choose to watch the ABC and SBS for the quality of content without the extremely irritating interruptions of advertisements, I reject the use of those channels for advertising of any commercial products. Indeed, I also am very tired of the promotional ads for their own programs. Let us have some space to enjoy quality television without having items in which we have no interest thrust upon us. Like so many other responders, I particularly reject gambling advertisements, which I find offensive in the light of the damage caused to individuals and families by gambling addiction.
The gambling ads are TOTALLY against the ethics of SBS They should be dropped immediately!!
I appreciate that the SBS (and for that matter the ABC of course) are being starved of funds. – We must stop being so apathetic and start to demand more funds for both community serving outlets – much as the Federal Govt. would like us to ignore the erosion of both our invaluable services.
I find the gambling ads absolutely dreadful! I am aware of the harms caused by problem gambling these ads should not be allowed on SBS.
Gambling should not be used in any form of advertising it is causing horrendous social and economic problems. Liberal party should return SBS funding.
I would like to especially note the following in relation to SBS on Demand, where the advertising does not seem to be as bad as other SBS transmissions, but cut in even more inappropriately. There may be runs of exactly the same ad 3 times in a row, or the Miele ads invariably seize on every showing, leading me to feel concerned my TV has gone wrong, or the screen may be damaged.
It is difficult to distinguish between SBS and commercial channels. It was bad enough when ‘sponsorship’ was implemented- ie ads between programs, but now it seems there is no limit to the number and timing of commercial breaks.
This is a publicly funded broadcaster. Get rid of the ads.
Reduce ads to increase enjoyment – simple!
I turn off SBS cos there are too many ads. It is too annoying watching something thT is dragged out by too many ad breaks of such LONG duration
I love SBS programming but watching is becoming unbearable. SBS on demand could be ad free but no, ads are repetitive and poorly edited in and out. Gambling ads and junk food ads are inappropriate
Why do they have to have multiple ad breaks in the MIDDLE of dialogue ! Surely it can be planned to have at the end of a scene.
Please reduce the promos and ads. Let’s keep distinctive, quality SBS programs without these. I would like to see all Gambling ads banned.
Advertising and inappropriate advertising just to promote consumerism has corrupted our counrty.
ENOUGH!…
We want better.
Stop the promotion of consumerism…
We have no more available space for junk!!!
No more space for junk in our lives, our landscape and certainly not in the minds of our young…
Cut the ads!!!…
SBS is public TV and should not rely on commercials
I guess we have to accept advertising on SBS, but the timing and number are enough to drive viewers away.
SBS promotions are particularly galling – why are they necessary?
Streamed movies should not be interrupted (or maybe once half-way through at most).
SBS is alienating its loyal supporters through this advertising (and don’t get me started on gambling promotions)
That’s a heck of a post about SBS. I got most of it. All I can say is, every time I tune into SBS – live and On demand, I’m always irritated by the number of ads, they even cut across sentences, and then after the ad the sentence repeats!
This has to be fixed.
I agree with many of the comments above… especially regarding gambling ads… This is morally wrong on any channel, but even more so on SBS. It makes me go back to the ABC whether I want to be there or not!!
The ads are often not age appropriate either. Way too many junk food ads. PLEASE go back to the levels that were manageable for viewers.
SBS has recently started promoting over the credits at the end of shows, compressing the credits naming the people who worked on the show and destroying the music written for the show. Is this an infringement of the show’s copywrite and probably illegal?
Please get the ads off SBS, the Government has a responsibility to properly fund public broadcasting. The Government should not be pandering to the rantings of the right wing commercial media.
SBS should be totally funded. Its a necessary telecommunications service. Should not have ads at all.
SBS is wonderful. I can’t live without it.
owing to so many intrusive breaks we are watching SBS much less than hitherto , sometimes recording a programme so that we can fast forward through the commercials
Definitely do not want any gambling ads. And yes, I am looking elsewhere more often, iView and Netflix…. to avoid ad bombardment.
The ads & promos are just plain annoying.I go off to do things at these times.
Why can’t SBS follow the rules?
The amount of advertising on SBS now is awful, and particularly on SBS on Demand, where ads often don’t load and stop the program – absolutely maddening!
SBS is fantastic. It is definitely the best place for all round news and events. It is better than ABC for news. SBS has great programmes. I suppose it has to have advertisements to keep it going. At least they are better than those seen in the hideous commercial channels.
I watch most SBS programmes and all movies by recording & then skipping the ads.
Adds are repetitive, frequently same one after another. Limit to 30mins. intervals.
Please…no gambling ads!
What is particularly annoying is that many os the messages in ad breaks are actually program promos. I thought the idea was that is provided better opportunities to advertisers- even if that is a good idea (which it isn’t) at least keep the break shorter and skip the interminable program promos
Way too many ads. SBS was never intended to be an advertising platform. Give us back our SBS
I am very surprised that legislation is supposed to limit ad breaks to 5min/hour, because in recent times, it seems to me that SBS is well on the way to being unwatchable due to excessive ad-breaks and long and unnecessary promos which are appearing in the middle parts of shows. SBS has changed so much over the last few years – at times it is almost distinguishable from the commercial stations (which are unwatchable).
The ads are extremely annoying as they don’t even proceed smoothly so you not only have to suffer through them but have to wait for them to commence and often they seize up during the ad and you can’t fast forward through them on NBN.
I would prefer no ads at all. Money can always be found if the goodwill is there.
I understand why SBS has advertisements, but they should be better targeted in respect to time and content. There needs to be some quality control too.
Pretty disappointing as SBS began with no ads, then a few (‘only good quality’)then there were more, most of little quality. We’re we surprised at this ongoing lowering of the bar? It’s not surprising we’ve all become cynical about political promises,.. given evidence such as this. But it can be fixed. Just stick to the promises made, then all would be fine.
Previously SBS had ads only between programmes. That was bad enough, but they were much less obrustive than they are now.
Ads compromise SBS as a new source, because of the conflict of interest between fearless reporting and advertising revenue.
If we want to watch 2 programmes simultaneously on ABC and SBS, we will record the SBS one and skip the ads later. Annoying but still better than watching on SBS on Demand, or the lengthy and irritating interruptions on live to air.
Gambling ads on SBS should be banned. Gambling is a net drain on society, an the government should not be promoting such a damaging industry through its broadcasters.
Please aboolich advertising on SBS.
Please stop the gambling ads. They are clever but this makes them more dangerous. They only promote a risky behaviour that can destroy people’s lives. In sync with banning tobacco ads, public health and well being should be guiding principles, particularly for public media organisations. Gambling, alcohol and junk food all of these cause harm and cost taxpayers via the health and social problems.
ALL GAMBLING ADDS ACROSS ALL CHANELS SHOULD BE …. BANNED …
IT SHOULD NEVER BE ALIGNED WITH SPORT … IT IS AN ADDICTION AND IS
RESPONSIBLE FOR UNTOLD MISERY AND POVERTY NOT MENTION CRIMINAL AND
VIOLENT ACTIONS IN THE COMMUNITY AND IN FAMILY HOMES.
Does this not show that SBS channels are struggling for funds to stay afloat? Or is it greed? Your views?
I have stopped watching SBS because of the ads. It is very disappointing as it has by far the most interesting films to screen, international news and Indigenous programs.
I cannot stand any longer the commercials following one after the other when I watch a film,particularly toward the last 10 to 15 minutes, breaking the spell and adding all this unwanted time to the screening.
It did not used to be like that and I wish viewers were not penalised for choosing to watch a less mainstream and more multicultural TV station.
I particularly object to the gambling ads. A community broadcaster should some standards and online betting is particularly harmful.
Agree with all the above
Bizarre logic at work here : A publicly-funded TV service needs advertising? Let’s find the funds to run it without commercial interference (you can be quite sure commercial interests put pressure on manangement policy..) The UK’s BBV TV runs without adverts because it raises its funds directly from the public through a license fee. The government cannot interfere – nor can commercial interests. The Australian method leaves the government holding the ever tightening purse strings, forcing channels into commercial hands!
The excellent, and even mediocre, BBC programmes are sold worldwide to make some extra money for the service. Not a bad business model.
The SBS provides a vital service as a publicly funded multicultural broadcaster. We should not be paying taxes to support disruptive commercials in its programming. It seems to be just a step along the way to privatising a public asset and must stop.
I was sick of the ads and turned the Television off – turned on the radio instead.
SBS attracts people who are thinkers, much like the ABC crowd who won’t be as easily swayed by ads. The advertisers are wasting their money on us!
Please give us back our original SBS and leave the advertising to the commercial channels.
We love all things SBS, but we are finding that we are turning of the TV to go to bed and read. The number of ads and promos is just ridiculous. We never watch commercial TV, because off the ads and generally don’t have the sort of shows we enjoy. Of particular concern is the display of the same add straight after the first. Are viewers considered drongos or some thing?
We now watch far fewer SBS programs than previously due to the now more frequent and annoying breaks. Much prefer ABC and now even Netflix, not for programme content but for uninterrupted viewing pleasure.
SBS is fast approaching commercial TV’s level of annoyance.
Once adds, promos were at the end of a programme. Now they are every 15mins, it feels as if I’m watching a commercial channel.
Whilst I understand that financially there must be adds, at the moment the sheer amount is totally beyond what I consider to be acceptable.
We need a government that supports our public broadcasters SBS and ABC!
That’s all what’s required!
The gambling adds are bad but the advertising of toddler baby milk isn’t good either. Just another junk food.
I record programs and fast forward the ads
The SBS should be fully government funded to permit everyone to see a program without commercial and promo breaks. Promo breaks can be between programs. It has become almost unwatchable. Where is the support for diversity, ethnic communities, multi-culturalism and diversity of media sources to support our democracy.
So distressing and disgusting right wing politics
It’s outrageous! When I worked at SBS we fought tooth and nail to keep ads of the air, knowing that the channels would be compromised once advertising was allowed.
I don’t mind the ads promoting other SBS programs so much but why do they have to be repeated during the same break? I HATE the gambling ads. So inappropriate on this channel.
During some programs we get the same promo at every break. It’s enough to drive you crazy. I vow not to watch whatever they are promoting so it has a counter-productive effect.
Devastating to see SBS cut by a thousand cuts – it is a national icon under attack by rabid ultra right wing politics
Definitely too many ads during a program. I understand that they need revenue to run and would be prepared to accept some ads at the start of a program. As it is I avoid watching SBS programs completely because of in program advertising. Agree with many of the other commenters that the ads also need to avoid promoting products or services that cause health or social issues.
I’m far more concerned about the confusing nature of SBS since privatisation. They seem to be changing their channel names (to meaningless marketing buzzwords) and channel numbers and technology too much and I can’t keep up.
Since SBS has upgraded from MPEG-2 to MPEG-4 technology I can’t watch 30 SBS HD, 31 SBS Viceland (whatever that is; not sure but “vice” doesn’t sound very appealing!) or 32 SBS World Movies.
Losing all those SBS channels is a pain, and my only option is to watch SBS online at SBS On Demand. This often buffers on my elderly laptop which can be really annoying.
Apparently devices purchased from 2009 onward should be compatible. Great.
What about those of us who can’t afford to upgrade our perfectly good tv, just because of some new technology?
What about those of us who love the planet and don’t toss out our perfectly good tv just because of some new technology, but keep using it as long as it works?
I am not sure how old my TV is but obviously it’s “too old”. Planned obsolescence strikes again! Discrimination against the poor strikes again!
SBS markets itself as so very inclusive, but it’s not true. You can be any colour, race or religion and that’s fine, but God forbid you are poor and/or want to protect the earth.
I used to be a great supporter of SBS, but it’s just getting too difficult.
I ONLY WATCH THE ABC AND SBS. AT LEAST THE ABC DOES NOT INTERRUPT AND SPOIL THE CONTINUITY AND DRAMA OF THE SHOW.
So many ads that our watching of SBS is much reduced. We also have problems with freezing of the ads which can last for minutes. It is very poor app when compared to others such as iView.
The poorly timed and excessive ad breaks on SBS spoil our enjoyment of some outstanding programs. I do not watch or listen to these ads. As soon as they appear I sigh and put my head down into my tablet.
Please, please, please give us back our original SBS with no or fewer ads. There are now more commercial tv stations so more ads. We don’t need them on SBS. They are frustrating and only drag out viewing time. When ads come on, I walk away, mute the tv or change the channel so I don’t have to suffer through the ad. Please bring SBS back to what it was meant to be….ad free!!!
This problem with ads on the SBS channels is not restricted to free-to-air, but also SBS On Demand – even the new look website has appalling ad breaks, now announced as “intermissions” !
Our country deserves a government funded broadcaster which is not beholden to commercial interests. Not to mention the obvious fact that ads destroy continuity by breaking the focus and they play havoc with TV programming. My 90 year old mother was getting quite confused the other night when her show didn’t start until about 7 minutes after the programme had advised.
As well as the excessive number of adds, adds that are repeated (the same add over and over again) are mind dumming. I suspect most people would just turn off completely.
SBS has amazing programs, literally amazing. The advertising is terrible, just too much. Australia needs SBS, why can’t it be funded better?
End privatisation of public services, especially broadcasting.
I have never been able to watch commercial channels because of the endless interruptions, so my go to channels were always ABC and SBS. Unfortunately SBS has now as many ads as the commercial channels, interrupting really good programs, movies and the news. It is infuriating that this good sender has become unwatchable. Even on SBS on demand.
Revenue raising bonuses for the big boys at the cost of good programming and watchers like me who have been with you forever, but no more, because you like the ABC are advancing a Socialist/Communist agenda which has become offensive to Australians who gave there all to build this Country.
Just close the doors you will no longer be missed!
Ad repetition within a single break is particularly egregious. I, and no doubt others, take particular care to boycott the products so promoted.
I never buy anything as advertised on SBS or any other station for that matter. Very few if any ads actually explain what the products are for and how useful they really are.
Much more than there used to be and it is really annoying now.
leave the excessive ads to the commercial TV stations
Normally, I would be interested in viewing so many of SBS’s programs. However, the frequency, repetitiveness and often poor quality of the ads means that SBS is rarely a viewing choice for me.
Advertisements for gambling, junk food and alcohol have no place on SBS and are at odds with the purposes of the station. Please get rid of them.
So many superb comments that reflect what I and our family members feel.
High time to change the way SBS program breaks are dished out to us. The great programs deserve more respect and so do we who watch it and embrace the high quality of content and presentation.
The glory of SBS was its lack of commercials and fabulous programs. Now it’s turning into another horribly commercial station.
I love SBS and SBS-Online but I am appalled that my favourite government TV provider is forced to increase its advertising to more than four minutes per ten minutes of content!
The increasing ad breaks send me back to our beloved ABC. Long may she stay with us!!!
Often I get a long delay at the start of every ad. This happens more during prime time. The delay can be more than 1 minute at the worst times, but is often 30 seconds or more. Very annoying, and puts me off watching at times.
The great advantage of a public broadcaster is the independence of private influence. Watching SBS is feeling more and more like watching a private TV station /commercial broadcaster which I try to avoid. I happy that with my taxes SBS is funded to be independednt in content and interruptions – even the inhouse promos are way too much – same with the ABC where you see 50 timers the same promos – as regular public TV viewer.
The original service that was in place in the very beginning should still be the service provided today.
There should be no ads on SBS, but even when they were introduced there weren’t too many.
Now however, the number of ads is unbearable, so much so that we don’t watch the channel any more.
I always liked ABC the best because of the lack of ads but SBS was OK because there weren’t many compared with the commercial channels. Now it’s terrible as there are constant ads and they hap[pen in the middle of a sensitive part of a movie or just anywhere and gambling ads should not be there air all. very disappointing.
Advertisements rammed down our throats within programmes are dumbing down our nation. SBS and the ABC are Australia’s free universities, giving measured, and intelligent information and an understanding of the wider world, with insight into people’s lives around the world, as well as within Australia. If advertisements need to be there, have a quarter hour advertisement period between programmes and people can decide whether they would like to see the brilliantly innovative advertisements, or not. I like to concentrate on a film or programme and absorb the nuances of filmmaking or complex subjects and it is impossible when bombarded with ads. I hate the way the programme starts with an ad after 10 minutes and after that the ads increase as one is more involved in the programme. It is an insult to we viewers. I usually turn the television off because I am thoroughly sick of the intrusion.
I agree the ads and promotions are too frequent. Mind you, the promotions on ABC need to be reduced in frequency as well
No thank you to John Howard and Richard Alston for attempting to destroy SBS and the ABC, both of which were world class. They still are, despite conservative government best efforts since such an egregious government.
Why must our last few free services also be corrupted by money? Who benefits from the public becoming fed-up with the last remaining services?! The government must pay the piper …. and we ALL suffer ….
Watching the Tour de France used to be an annual highlight for us. The intrusion of ads, repeated without variation and of promos now make it totally tedious.
The sbs of old was a pleasure to watch, along with the abc due to lack of advertising. So frustrating to see sbs being forced into this predicament.
Apart from the responsibility has for defining, expressing and advancing the multi-cultural nature of contemporary Australian society the SBS has an excellent range of drama and films from around the world. The current level of advertising is ridiculously high and in some cases disturbingly dubious if one considers the number of ads promoting gambling, for instance. The SBS is unique and should be entirely free from the sort of advertising that consistently comprises its values. The government is, as usual, lazy, wanting something for nothing and demanding commercial rigour in an environment that should be entirely public and culutural.
Dr Edward Hills
SBS is not a commercial channel – why should viewers have to bear the annoyance of frequent disruption to watching the news or a show? CL
It used to be SO wonderful when there were NO commercial breaks on SBS.
Now there are far, far too many.
It’s outrageous that SBS is not better funded by the Commonwealth Government – it provides such an important service on so many levels for the multi-cultural make up that is Australia.
We wanted more migrants. We were lucky enough to attract an outstanding calibre of individuals who are hard working contributors to our society. They deserve to be serviced by the mission of SBS. A person’s language is part of what they are and it is so important that sub-cultural groups in our communities hear their native language and see their culture depicted in stories from or about their country of origin. And the rest of us gain in experiencing the richness of so many other cultures being brought into our lives.
The ad breaks have increased beyond acceptable. Used not to mind but now watch on demand as a matter of course. Increasing them to the extent they now feature has the effect of making me switch off or become resentful, so a waste of time and money expended.
The adverts are inappropriate to the shows as they were meant to be when this was introduced.
The adverts on SBS On Demand are arbitrarily placed. They cut straight through the middle of characters sentences.
Stop taking ads from Gambling Companies. They trade in human misery.
Have atopped watching SBS because of the excessive advertising. Now only watch SBS On Demand, and use an Ad Blocker!
I also find the extensive advertising on SBS to be not only disruptive but unwanted! It used to be wonderful to have an advertising FREE SBS no longer though ! I’m finding that I prefer to play with my IPhone these days!
Far too many adverts and self promos on SBS now, I don’t bother to watch very much now.
Advertising disrupts and pollutes the programming. SBS should be publicly funded.
There is ample evidence showing online betting can be harmful.Why is our taxpayer funded agency promoting online betting with their advertisements? Time for some changes
SBS is a federally funded broadcaster. The amount of advertising – much of it inappropriate – is a disgrace. This is especially true of movies, which are decimated by repetative station idents, ads for its own products, as well as all the other inappropriate commercial companies, in my view such as Coles and NAB. They are a disgrace in my opinion.
It shows little respect and sensitivity to the calibre of movies SBS screens (we were noticing on World Movies most recently) to fragment them with so many commercials and promos. I wonder why it has to be this way. Does it, really?
Until the government requires diversity and balance from the commercial networks (not just by a self-regulated code) & online content providers, it is inappropriate for our 2 national networks to not be 100% financed by our taxes and therefore dependent upon staff and content cuts and advertising.
Double standards again from the regulators.
So incredibly sad to see what has become of SBS. Not only are we bombarded with adds but gambling ones at that, it’s unconscionable.
best programmes and lineup of all free to air.
Ruined by ads and their implementation.
Turned off now and watch irregularly
Commercial channel already carry very heavy advertising – most of it is ignored.
Commercial TV and SBS don’t seem to be much different now in terms of ads. I don’t actually watch the ads because I stopped watching TV in real time – I tape the few things I want to watch and skip the ads. I didn’t mind the promos because it often made me aware of something that was coming that interested me, but I seem to skim over these now as just about everything I watch is taped.
I remember Senator Steven Conroy years ago claiming he would ensure advertising would be reduced on SBS. Didn’t happen!
Let’s go back to the original SBS where ads were only broadcast between programs, not within. Even better …. no ads at all!
SBS – Special Broadcasting Service. How can it be special when it’s relying on annoying and senseless repetative advertisements for funding? The service should have adequate funding from the Australian government to meet the needs of a large segment of Austalia’s population which have links and interests outside but who have put down roots here.
When I migrated to Australia in 1989, I noticed that this was the only TV Channel here that had non-Anglo faces on the box. No adverts then. Has over the years had some programmes of srength and depth engaging a wide audience. The World News was actually World news not the Australia-centrist news found even on the ABC to this day. What we need is for the advertisements to stop.
I have seen the same ad 5 times tonight! It’s infuriating!!
SBS is insulting us!!!
SBS is (or always was in the past) a great channel, a respected programme maker and not a tawdry means of delivering audiences to advertisers. There are more acceptable means of securing funding than pandering to the lowest common denominators of the advertising industry. Think again!
Much as I like SBS programs I feel driven to consider commercial channels because of my frustration with excessive ads and promos.
I could almost stand the ads if they were bunched on the half hour but the randomness and mindless placement is infuriating. Has to be an extraordinary show for me to tolerate the ad abuse, usually head to ABC or Netflix in preference
SBS has far too many ads which disrupts & spoils a relaxing & enjoyable evening for my family & I.
Place the ads at the start and end of the program not in between.
I seldom watch SBS because of the advertising. The programs are constantly interrupted and one looses interest.
I do not watch commercial channels for the same reason.
We sit down to watch SBS in the evenings only and have been saddened and disturbed by the number of ads being run. It is completely spoiling our enjoyment of the programmes we watch. SBS is a wonderful multicultural medium – the Government should do more funding for this amazing service.
There are way too many ads on SBS in general however what really annoys me are: ads that are repeated over and over again (sometimes in the same ad break), ads for gambling (unconscionable), ads that show aggression and bullying (eg M&M ads), too many ads in a break (sometimes 7-8!). I now record anything I want to watch so I can fast forward through the ad breaks. This makes what I want to watch bearable but it still annoyingly disrupts my viewing experience.
Adverts promoting gambling normalise betting, adults, and young kids, eyes glued to devices to see athletes and horses and dogs exploited for profit. Dumbing down the voters, people reduced to cash cows. Multi cultural new Australians must get a very bad impression from the excessive advertising.
The program interruptions on SBS are incomprehensible. They are so frustrating that they can ruin a movie. I watch SBS less often as a result.
Gambling ads should be treated like nicotine ads and banned from all advertising leave alone SBS. Give back our ad free SBS.
The government should fund SBS properly and get rid of all advertising
Do we need SBS program promos every as break??
The format is so annoying we almost never watch live, and now the ad/promo built into streaming is as ridiculous. It’s so annoying we’re slowly but surely switching off from SBS content all together.
I am particularly concerned about SBS advertising gambling sites – totally wrong!
SBS quality programs are being ruined by intrusive ads. This scatters my concentration span.
The only way to watch SBS at present is to record a program on a PVR, such as a Fetch box, and watch it later. You can then fast forward through the HUGE ad and promo breaks. Inconvenient but better than sitting through several minutes of mind-numbing nonsense.
It’s very sad that things have deteriorated to such an extent.
There are way too many ads,they are repeated incessantly and have little that is interesting or clever. They are way too loud. They disturb the flow of the program. Most are utterly insulting. Gambling, drinking and speeding cars (with our road toll?) should have no place in front of the public, let alone SBS.
In particular the movies are ruined by ad breaks. I love to watch On Demand movies but even replaying segments is near impossible because up to 4 ads have to be sat through each time.
Please restrict ads to before and after the movie.
The artificiality of the breaks is not significant and invites an SBS sop to viewers but improving the ‘naturalness’. There is nothing natural about the interruption of a drama or comedy or documentary by some piece of advertising material, usually noisy and off-key with the content you were following. It was barely acceptable when it came in-between programs. and probably little worse that the ABC’s constant repetition of its self-advertisements.
Don’t enjoy movies as much as I used to because of advertising disruptions. Also there are far too many graphic adverts asking for donations by organizations that have very high administrative costs
adds are very long break now.
Unhealthy food etc being advertised.
If, and I say IF, there have to be ads, there should never be ads for gambling. They are unconscionable in our society!
Ads disrupt programs and if they have to be run, should be limited to the beginning or end of programs. I’d much prefer that there were no commercials, but if there has to be, these should be minimised and the agreed limits not exceeded on an hourly basis. If there have to be ads, more screening of their nature and content should apply, such as outright prohibition of gambling ads and junk food ads, irrespective of the time of day.
No gambling ads!!
Also, there are too many ads which disrupt the continuity of programs and take away the pleasure of viewing interesting and informative programs.
I really enjoy SBS programmes, but the ads are really very irritating these days. I remember the days when the ads only seemed to be between programmes – now they seem to appear every few minutes.
ADS ARE A PAIN IN THE NECK SO AT LEAST STICK TO THE BLOODY LEGISLATION
We can’t allow our SBS to go the way of money grabbing commercial stations – they’re so infuriating to watch!
The wonderfully diverse programs on SBS deserve to be commercial-free.
The ads on SBS are a disgrace. SBS should be independent of commercial interests and this is jeopardised by advertising. It is clear that the quality of SBS programmes has deteriorated significantly. All advertising should be removed from SBS. It should be like the ABC.
I love the programs on SBS but I hate the increased number of ads. Please stop the rot and enable us to view quality programs without mindless interruptions, often promos.
I think SBS and the ABC are utterly vital for the Australian population. Especially their news (and similar) programs can be trusted, and essential viewing.
I understand they need advertisements for their income – and that is why I put up with than. If removing their ads ends up with no SBS, then I vote for the ads!
Whatever happens, we NEED the ABC and SBS to continue, and to be as free as possible from Goverment interference! For instance, it is sad to hear Scientists say that they are not allowed to write about their findings, and their concerns, regarding our climate which is changing. Scientists need to be listen to – and we want SBS and the ABC to allow them to have a voice.
The quality of the programming is not good enough to compensate for the constant and interminable ads and promos (which are just ads for SBS). This station used to be very good. I watched it from preference. Now there is barely a programme worth watching on 4 Channels. May as well close it than have this crap
I had no idea that SBS was allowed only 5 mins.of ads. per hour.I must sit through muliples of that. The thing is that hardly anybody listens to ads.even if they keep the sound on and advertising agencies know this (ref. Gruen).
If I were to phone up Management and tell them how great I was for 15 mins. per hour I would earn an AVO for harassment.
We have been quite disgusted at the growth of advertising on SBS. Remember when we were told it would only be at the beginning and end of programs? Remember when we were told
that the ads would be appropriate and tasteful and reflect community concerns? Now it seems anything goes. It is hard to remember that SBS was such a breakthrough when it was
established although we do enjoy the news hour.
Please remove ads during programmes – I record all SBS so I can skip them but I notice the frequency and disruption even then.
Love some of the programs on SBS, but I have stopped watching it because of excessive ads. I have decided it is just not worth the tedium of the excessive adverts. Have obtained many of these programs as DVD sets down the track (I dont mind wiating for them) and luxuriate in ad free viewing. Would go back to SBS if it was full publicly funded
Commercial channels are far less likely to screen films like Foxtrot or A Breath Away, intricately constructed movies whose thematic and emotional impact often jar with the bright loud commercials- I don’t mind promos so much, but probably like them even more between films. I doubt commercial channels would bother with any subtitled films. SBS on Demand is better, at least the ad breaks are only a minute, but I do prefer the HD of original screening, not sure which is the better trade-off, but shouldn’t have to make a trade-off at all.
Apart from the excessive ad breaks, what is turning away from SBS is the over blown station identification music. It’s earth shaking volume angers me so much I turn the chanel off. And I don’t always return when I think the noise is over. Please control the volume. Turn it down a few noctches.
I am particularly disappointed in the frequency of ads being shown during prime time viewing on SBS.
It has been quite noticeable during “The Feed;” which is a little frustrating, as the time wasted on extra advertising could be used by providing more info/entertainment on the aforesaid program.
As an aside, both my husband & I are against any ads promoting gambling of any description!
SBS along with the ABC are our most watched TV stations; please consider slowing the constant interruptions of good programming with too many ads!
Far too many ads and too many ad breaks.
My DVR works overtime with SBS as I prerecord programs and use the Fast Forward..even this takes time and is annoying.
Return SBS to the Australian people. get it out of the grip of greed driven advertisers — in my view, eco cidal, socio pathic irresponsible criminal Capitalists. A community owned and controlled SBS can be financed by community subscription not advertisers filthy money. End the SBS TABOO on avoiding Australia`s biggest problem = Lib Govt excessive worlds highest eco/carbon footprint population growth caused environmental decay, bio diversity destruction and Lieberal Govt re colonisation and social engineering of Aust by abusing our traditionally humanitarian, multi cultural and responsible immigration system now under the Lieberals corrupted,hijacked for crony Capitalist profits and right wing social engineering of former safe Labor electorates by almost only importing wealthy BOURGEIOSE Upper Caste Indians and Han Chinese non unionised workers, students, their welfare rorting families at un sustainable ,destructive reord high intake while genuine refugees and asylum seekers with no cash are locked up in off shore prison camps.
The same ads repeated over & over! And why do we have gambling ads on any channel far less a public broadcaster?
SBS has always been a really good, quality channel – essential! And I understand that funding has been decreased. But this advertising blitz is awful, and ruins the pleasure. When streaming, it is an absolute pain, and puts me off.
Thank you for the brilliance of your programming, but please, isn’t there another way to increase revenue? We need to blitz this government instead with calls and letters to increase their support of our brilliant multicultural channel!
Way too many ads. Give us OUR old SBS the way it used to be. It’s meant to be a government service for the community, not a money spinner for business. I hardly watch SBS now purely because of the ads. If they wreck the ABC the same way, it’s just going to be DVD box sets from now on.
Far too many ads on SBS, so unfortunately we don’t watch it as much as we used to. It just doesn’t make it enjoyable evenings viewing.
Ads are bad enough but the proliferation of gambling related ads is unacceptable
SBS should not needs adds to maintain its’ financial stability. The government should once again adequately fund this public broadcasting service that serves all Australians so well.
This appears to be a blatant attempt to please the media moguls. There as many promos as adds and that just seems a way fill a break enforced by external pressure. Go back to serving the people, not media power barons
I’m so over having the food taken off my plate when I am eating dinner or breakfast because of some poor starving person. Also, how long is it going to take for that charity to rescue that bear or tiger? And, is it not time for the LNP to properly fund children?
Honestly, if this is what it takes for SBS to survive, the LNP government should be voted out.
And, if the politicians think that “the Block” and listening to Alan Jones ranting on is informative, educational or entertaining, they have lost the plot.
To all politicians, stump up the money to provide us with a decent broadcast service. After all, you seem to always find the money for your pay increases!
At least I haven’t seen an ad for men’s erection enhancement drugs for a while but one would really expect a complete different management of commercial revenue for a station like SBS: less breaks, maybe longer, be more selective with the type of products that are advertised. SBS has more of an ethical responsibility than the other commercial stations (there you have it, SBS is a commercial station).
Okay, one more thing: can SBS scrutinise their documentaries more. Too many documentaries that are complete rubbish with too much pseudo science. Sorry, went off topic here.
Too many breaks, repetitive. advertising, the worst ones are about gambling. I always like to watch SBS but I fear for its future. SBS news is the only TV Chanel to inform comprehensively on the world news.
too many ads especially gambling ads on this non commercial channel Give us back the content.
SBS used to be a delight to watch. Thats what made it stand apart. full length shows with no ads. The programs are still a delight, but the ads keep repeating, breaking up good programs. Can SBS not still be a standout? Cant they put all their ads at the end of each long program. and WHY SO MANY?
I have always loved SBS and the ABC but lately I find the ad breaks way too frequent and distracting on SBS. Even Ondemand the number of breaks is infuriating. I find myself just muting them and waiting for the program to resume.
Less ads between programs would be preferable.
The advertisements come thick and fast and ruin the flow of a movie or sensitive documentary. I will try and record programmes, so that I can fast forward the ads. And, the ads are very loud and tacky and can be quite disturbing when you have been engaged in something like The Kings Speech or the documentary on Hiroshima. It’s awful.
I find the gambling ads in particular are worrying — they are unethical.
There are FAR too many ads all together leaving teh viewing disjointed, so sad SBS
The adds in general make viewing disjointed, the gambling ads in particular are worrying — they are unethical.
So sad we have had to stoop to this
Too many adverts, too often — repeat, repeat, repeat. Disrupt, disrupt, disrupt.
Thankfully one advert was funny enough to warrant watching it five times during a streaming session recently!
love sbs love the movies hate the ads, hate so many promotions for the upcoming shows, hate commercial ads and even their repitiveness, we record everthing now so we can skip the waste of our time. Real shock when we occasionally watch live TV
Id rather pay a small subscription and have less ads.
I do notice is the repetition of the same ads… zzzzzzzzzzzzzzzz AND endless self promotion
If there is a programme I want to watch on SBS in real time…I give up and watch it on demand, Because the ads are much less, or shorter there.
SBS often advertises forthcoming programs., and then a repeat of the same ad.. There is no need for more than one per hour, as regular watchers of SBS keep up to date via regular emails.
SBS is unlikely to attract viewers from the commercial stations.
How about a 10 minute ad break between shows.?
Pam
Even if some ads are necessary for funding purposes surely there could be less of them and they could be better structured so as not to disrupt the flow and rhythm of programs
The frequency of commercial breaks on broadcast SBS is excessive however it is still worse on SBS on demand. While there is too many what’s worse is their inappropriateness, add to that the need to reestablish the closed captions, which takes several tries every time there is a commercial break amakes it all too hard to watch what are some of the best viewing available on the box. They could, and should be able to do better
Dreadfully amateurish station promo breaks with static ads. Why bother? Looks shabby and just an irritating nuisance.
It forces us to record our programs, then watch later and fast forward the ads.
Too many ads, too many promos. The endless repetition of certain really annoying ads drives me mad. I do want to know what programs are available on SBS, but the way these are promoted so quickly, I find it incomprehensible. So why bother to wreck our viewing with incomprehensible promotions. Just put a list on a website.
SBS is a government television station and as such should be funded properly. I am at a loss to understand why ads were allowed in the first place, let alone the increase in advertising. There is enough profiteering and greedy grabs for money by government already. This station is paid for by OUR tax dollars and should be run in a way that is in concert with the peoples’ wishes, not the government’s wishes.
With regard to advertisements for gambling- advertising cigarettes, alcohol and drugs is banned in Australia presumably because those things are not in the interests of the people. I find gambling advertisements fall in the same category and find any gambling advertising deeply offensive. I also agree with some of the other comments that decry the ‘normalising’ of gambling by advertising.
In the ‘Post Comment- it’s mathS, not math. We are not Americans.
Ads and streaming promos are a pain. Pity, there are some very good programmes
Remember the days of no ads on SBS!! I turn off mentally when the ads come on so not sure what advantage they are !! I hate the gambling ads and they should be banned. It is a downward spiral of more and more time given to ads. I watch the ABC and SBS because of their ethical programming and multicultural content not to have inane ads pushed at me.
I loathe the adds, both the content and the quality. It’s almost a relief to switch to ABC!!
Absolutely despise advertisements interrupting a quality program, becomes a real turn off to watching SBS. If I wanted Privatised television I’d watch one of the crappy commercial stations.
I am happy to pay for public broadcasting through my taxes and yes I am a PAYE tax payer.
If anything good has come out of COVID19 it shows that public can be better and is good, private and for profit is narrow, self interested and puts the public interest in an inferior space.
Come on SBS you can be so much BETTER.
We are a rich country that depends on immigrants to sustain the economy. SBS plays a vital role in integrating and accommodating these people. It deserves public funding to achieve this, rather than become another government cash cow. The inclusion of gambling advertising sinks it to a new unconscionable depth where nothing but money counts.
I’m not a regular tv watcher and hadn’t watched SBS for years so was surprised to even see advertisements. The was appalled at how many there are. This is supposed to be a public station. I gave up in the end because of the number of adds.
I enjoyed the amazing movies and SBS content but now just switch back to ABC or free view television due to the excessive ads and junk displayed while watching even the SBS news. its as if I’m watching the commercial channels.
There should be no gambling ads at all on TV, anywhere.
The number of ads in a single break is quite absurd. It’s not uncommon to see the same ad twice in the one break. I especially object to the gambling ads: we have a major gambling problem in this country and ir is unconscionable to further promte gambling when we’re suffering lockdown fatigue. The other night, I unloaded the whole dishwasher in one program break! I’m prepared to sit through two or three ads, but once it gets to 10 or 12, I leave to fold the washing or sone other chore. I do not stay to watch. It’s a waste of their money and our time, and disrupts the program terribly.
There are far too many ad breaks on SBS.
Could you please limit to every 30 minutes. Please less interruptions!
Please return our SBS to what it was originally intended to be.
LESS viewers = LESS advertising dollars and SBS is losing viewers due to us going elsewhere to see ad-free shows (like ABC, paid streaming, DVDs). I don’t mind paying a bit to see a show, but I thought we had already “paid” for SBS via our taxes. Fed gov needs to fund it properly.
While some limited number of ads was normal between programs, before now it is ludicrous! And before the advertising content was vetted so that more ethical ads only were allowed. NOW screening Gambling Ads is the most unethical low of all. Even Alcohol! Disgusting. We want our SBS back to where it was before…..an ethical educational publicly funded channel.
I find the gambling particularly offensive. Also the commencement of ads during a program does not align with a natural break.
SBS was never intended to be funded through commercials. It is a public service and should be properly funded by our government.
I can’t stand the disruption from too many ads so I record anything I want to watch and cut out the ads without viewing them. It’s a nuisance but it’s the only way for me. It means I probably miss great programs that I might otherwise have seen accidentally so that is a shame.
Turning away from SBS because of the ads is exactly what the ‘Sell it off’ brigade wants, making money meanwhile with an avalanche of ads that they know we hate. Look at Mastermind – it’s about 40% ads with two breaks in 30 minutes in a show that’s already battling, with that doomy music and gloomy set.
Just as John Howard stacked the ABC board with his xenophobic cronies and sacked all the journalists from it, we can hear the SBS board: ‘Look, nobody’s watching. We’re wasting our money funding it.’ But it’s OUR MONEY, OUR CHANNEL. They know we’re a minority, older, better educated and less gulled by advertising audience. Post Covid-19 we’ll be even fewer. It’s a Catch-22 situation.
The ads are so disruptive and intrusive.
I find watching SBS is very frustrating and there definitely seems to be far more ads than the number they are supposed to have. And why is it that you can’t fast forward through the ads on SBS on Demand?
It’s also interesting that since SBS has been carrying advertising they have become a very Anglo centric broadcaster. I am a fan of British TV shows but SBS increasingly looks more monocultural than multicultural.
The only way we can watch SBS now is by recording ALL the programmes we want and watching them by fast forwarding through all ads and promo breaks. Amazing how much of your life you get back doing that. Sorry SBS you are going to have to look at your strategies around this issue or continue to lose viewers which would be a great shame as you are a wonderful provider of news, sport, entertainment and information.
I avoid SBS now as the ads come way too often. They also show the same ads over and over. If I really want to watch something I note the multiple ads and make sure I never support those businesses.
We need more funding and Less ADVERTS.
This information is not totally surprising because SBS does not appear to have mandatory oversight on its content compared to the scrutiny faced by the ABC. Furthermore it is apparent that Liberal governments most especially do not like investigative journalism so it is preferable for privatisation to occur so that manipulation can be undertaken. Such undertakings are akin to totalitarianism but not acceptable in democracies with proper controls in place. Of course though like every industry that is allowed virtual self regulation then the media run amuck from the top down.
Too many breaks crash into the program rather than at a more ‘natural’ timing. Obviously dominated by technology rather than human sensitivity. There was a time when the ads were bunched at either end of a 30 minute program or 30 minutes apart which is at least less intrusive. I know SBS is forced to compete with ads on SBS because SBS can’t run a channel on the money SBS receives from the government, but there must be a way to do it that doesn’t ruin the programs.
Brief pomos *between* programs (like on the ABC) is ok. Ads inserted into programs is the main reason I no longer watch commercial television. Make SBS entirely public-funded. And do the same with universities, while you’re at it.
If we want SBS and the ABC to survive they must have some income Advertising is it as long as they do not exceed that allowed to the Commercial networks We must keep SBS and the ABC
SBS are being funded by a conservative government.
SBS forgets its original charter that its birth was to give a multicultural experience to Australians & newcomers to our country. Stop the ads & fund it correctly with fairness & dignity.
Please let SBS be, an advertisement free channel as originally intended.
The repetition and frequency of ads, often in the same sequence is irritating, and often very disruptive. gambling ads are particularly offensive, given the ethical implications of these. Please show some intelligence when selecting advertising material
The recent and ongoing tragic pandemic has adequately displayed the government’s deep pockets. The relatively tiny amounts of money required to fund high quality ad free public broadcasting means that this issue is a no brainer…Do the right thing and if you’re not going to remove the ads completely, at least follow the rules
It’s especially bad with SBS On Demand, the same adverts are repeated over and over until it becomes unwatchable. Sometimes these are promotions of SBS programs – it’s become so that we avoid watching SBS.
The problem is underfunding by the national government. How can government funding be increased up to previous levels? Could state governments contribute as well by giving info about their community services?
The gambling ads are particularly offensive, targeting migrant communities.
I am really disappointed by the impact of too many adds on our loved SBS. I feel many of them are intrusive (betting adds), all are repeated far too often and they are interupting the programs too much. We love the SBS but are struggling to put up with the adds.
There are too many ads on SBS. It spoils the viewing enjoyment. The repetitive ads are extremely annoying and puts me off watching SBS.
Don’t watch SBS much any more because of the ads – a pity, since they are the only station which has 3 “channels” in HD!
I am just not a ad person. I am now watch ABC TV more since the move to advertising on SBS. I don’t do commercial TV whatsoever b
Gambling ads, repetition, unfortunate timing (e.g. ads for SUVs in the middle of a tragic car accident resulting in death in the movie or news report) that make a mockery of the movies. All this advertising has only resulted in us vowing never ever to buy products which were advertised on SBS with inane, annoying clips. We dream of the pre-commercial days when you could sit down and actually ENJOY a broadcast. This is before I even mention that most of the content of our ‘multicultural’ broadcaster now relates to UK-produced content or endless sport events, neither of which represent out diverse world.
It’s all very well criticising SBS for its advertising. But I assume that they are trying to stay in business. Your criticism should be directed at the government which refuses to properly fund its public broadcaster. A better way still would be for everybody with a tv to pay viewing fees.
Gambling ads should never be allowed on a taxpayer funded television channel!
All good. Get rid of the ads during programs.
The increase in ads on SBS is well beyond anything that is reasonable and substantially devalued the network. In the past, SBS News has been the main source of reliable information about what is happening in the wider world but is now so disrupted and fragmented by ads that I can only bear to watch occasionally. Gambling ads should be banned.
I concur with all the aforesaid comments and add another annoying feature – the endless repetitive, gross ads that spoil my viewing of movies and series on SBS on Demand. The prize for the most annoying one ever goes to Telstra
SBS should be the same as the ABC and have no advertisements.
Basically we have changed to watching ABC because of the saturation point of adverts – total disruption and not something we would tolerant.
End the ads on SBS
Why wait for the COVID-19 pandemic to end? Let’s roll SBS back to the days when you could watch a full length movie without an advertising break – and lets do it NOW!
There are way too many ads not just on SBS free to air TV but also on SBS on Demand. Their appearance is barely contrived let alone natural. They just interrupt out of the blue, repeat in the same break and make it as bad as watching commercial television. SBS is supposed to be Special. I too dislike gambling ads as they are of no good value to anybody. I would prefer there to be no ads on SBS. If they must be there, do as I saw in Germany back in 1975 with a few minutes between programmes, not within.
Almost at the point of not watching because the ad breaks are so disruptive to the flow of programs…now over the top maddening…and get rid of the gambling ads please. SBS you are ruining what was once our best source of tv programs.
End Australian Media Gag Laws!
At the very least, no more gambling ads.
A beautiful program is suddenly destroyed by what appears to be constant interruptions. Please bring back the SBS we love.
With the ABC releasing very few new Drama programs, we’ve turned more to SBS to watch quality drama but the excessive adds make it very annoying. Constant repetition of the same add and poor editing by the editor makes viewing very frustrating.
I agree the gambling ads are the worst – not only their malign social influence but they are so crass. Quite a few of the others are too – not very much different from the most low-brow commercial stations. If only they only took ads that were really funny or entertaining in some way, or had some artistic quality that you could admire! There are one or two like that – but then SBS repeats them so often they lose their appeal. And there are some really irritating ads: back in March/April I think they had a really irritating add for Trivago, which was repeated in just about every ad-break – after a court ruled the German-based giant, Trivago, had misled consumers about hotel room rates. SBS fans should expect that it only shows programs that are of real quality, either intrinsically or because they support genuinely multicultural advertisers. SBS should make it a privilege to show only good quality ads, for a limited number of times (once per hour, maximum three times per 24 hours) and charge a lot, if they need to make money because of government under-funding.
Love the SBS programs but the ads and promos are just too much. Frustration sets in and it’s back to ABC. Would much prefer to watch SBS, such diverse content.
I am watching SBS much less now than I used to because of the frequency of the ads. Even streaming a program on SBS On Demand is highly annoying because you have to wait for the ads to stop before you can even start viewing the program, and then its continuity is interrupted by frequent ads. One ad might be tolerable, but these days it’s often three before the program resumes.
It’s actually worse than watching free-to-air commercial TV.
And why all the gambling ads? Surely this is against SBS’s values?
I have not watched any program on SBS for years now simply because I can’t bear the advertising, particularly the mid program interruptions.
Please bring back the SBS of old. I’m not even sure why advertisers would want to waste their money when so many viewers are switching off.
SBS was fabulous and something to enjoy.
Then greed ruined all that with ads.
PLEASE cease and desist!
In my view, I think advertising on SBS has corrupted the SBS brand.
It is impossible to watch serious programs without stupid interruptions.
Stop this as soon as possible.
SBS and ABC are Public Broadcasters and should be properly funded, not have budgets cut! Also, SBS, please delete the forced login to SBS On Demand. Make it login free, like the ABC site. Then more people would watch.
SBS is so essential to viewers having a broad view of Australia and the world. It is important that it is appealing. Commercial ads in particular diminish its appeal.
SBS has many terrific programs. The excessive and repetitive advertisements are annoying and spoil the viewing experience.
There are so many great programs on SBS – movies, documentaries, series, food shows etc. unfortunately the ads are incessant and repetitive. Can’t watch a a whole movie without ads! If you’re watching a series and what to go back and rewatch a section you have to rewind, fast forward and go through all the ads – very frustrating.
the ads are fatuous, infantile and repetitive and turn me off completely rather than be influenced
The amount of ads and the amount of commercial breaks are incredibly frustrating. If the powers that be want us to cease using this channel, they are definitely doing all the right things to destroy its patronage. The volume and frequency of ads and breaks really disrupts the programs you are watching, making them almost unbearable.
I would be happy to pay to have an add free SBS and On Demand services.
Although I enjoy the content of many SBS programs, the constant ads and promos discourage me from watching this station. So it’s either ABC or a book.
Commercial ads are not for the benefit of viewers, but are an intrusion into the creative content and flow of programmes. The current situation is not acceptable.
I would prefer SBS didn’t have any ads. It should be funded properly. But if they must these, they should be discreet and within the law.
The frustration of programmes being constantly interrupted makes view impossible so I no longer bother. So many great shows spoilt by advertising. It was so incredibly good but now ruined.
I haven’t actually ‘timed’ it but it seems that the section between the American “news” and the PBS Newshour at 1pm (Central Au Time) is about TEN minutes long – broken only by a 5-10 second ‘headline’ from the American News anchor every now and then.
and yes, i agree that the number and length of advertising (and especially promo’s) are far too lengthy and intrusive – mainly because they are for products that I don’t need, don’t want, and can’t afford.
Get rid of the ads, its publicly funded!!!
The gambling adds in particular are disappointing and inappropriate when SBS is generally the place to go for community connection and learning about the wider world.
I still love SBS especially their news service but could you please leave the advertising to the commercial channels. Viva La SBS xxx
I love SBS news and the innovative programming but the ads do deter me from switching over from the ABC. The incessant advertising spoils the continuity of programs.
I watch SBS on Demand regularly. The ads here are limited to three but the system that loads them is inadequate. Frequently the ads fail to load correctly resulting in the program freezing for which the cures are, at best, to reload the program, at worst log out of On Demand and start again. Sometimes neither cure works. I agree this could well becaused by the inadequate NBN that the LNP government introduced in the misguided claim of ‘efficiency’ but the net result is to undermine the purpose of the ads: rather than being tempted to buy the product, you curse the company for undermining your viewing. If SBS has to do ads, for heaven’s sake make sure the system actually works.
SBS is a culture here in Australia. Its unique programmes and thought provoking documentaries are a must in this society of mass commercialism. We have such a diverse population that delivers news and entertainment to many cultures.
No ads or less ads.
I no longer watch SBS live, because of the constant programme breaks and repeated advertisements. If only one could fast forward live TV. Please bring back the original quality of SBS for our sanity!
There are way too many ads & promos. Additionally, the repetition is unbelievable. I won’t be watching SBS for much longer as a result of this. It is just too too irritating!
I love the SBS and its programs but find the the number of ad breaks very annoying. It is the number of ad breaks, much more than the total ad time, that I am concerned about.
It is disappointing to see so many ads on SBS. Even on watch again the programs are disrupted. I choose not to watch commercial TV and with the defunding and declining prog being made by the ABC, I am sad to see what is hppening to SBS.
While the number of ads is excessive, it is the constant and repetitive promos that frustrates me the most. There are few enough programs worthy of watching on SBS since the new ad structure was introduced. It just adds insult to injury to be incessantly reminded of the crap that has replaced it.
I agree there are far too many ads and promotions, often repeated in the same break, very annoying.
There should be ONLY ONE AD BREAK per program, it’s OK if it is longer.
ALSO at the end of movies on SBS World Movies, during the credits ONE THIRD of the screen is taken up by a promo of the next movie, MAKING IT VERY VERY DIFFICULT TO READ THE CREDITS. It is very frustrating, for example, I like French cinema, also Spanish, Italian, well, European, and Latin American, and Indian… and I like to know who are the actors and directors…. but I cannot read their names, reduced by the promo the letters are too small. VERY ANNOYING.
We basically watch SBS normal programs and do find the ads quite intrusive, more than they should be. Please get rid of the gambling adds! The promos are infuriating.
SBS has great programmes, but advertisements need to be once again restricted to being between programmes. Some promotion of upcoming programmes is a good thing, but not when it becomes excessive. These self-promotions should also be between programmes, along with advertisements. Gambling and alcohol should not be promoted by SBS at all.